From Ivory Towers to Everyone: A Technical Reading of the DeepSeek R1 Report
Introduction
When DeepSeek R1 launched on January 20, 2025, the release was initially quiet. Then, on January 27, DeepSeek overtook ChatGPT on the US App Store. After that, the discussion exploded. Suddenly everyone, from AI researchers in Silicon Valley to ordinary users far outside the tech industry, was talking about this company from China and its unusually strong reasoning model, R1.
What made the moment even more striking was the timing. It had been less than a month since the release of DeepSeek V3. R1 did not just improve performance and cost. More importantly, it changed the conversation about how reasoning models could be trained and distributed.
R1 reshaped the AI landscape the moment people realized what it represented. Compared with V3, it was not only a stronger model. It was also a direct challenge to the industry's increasingly closed posture.
Jim Fan pointed out at the time that DeepSeek seemed to be carrying forward the mission OpenAI was once supposed to embody: open AI.
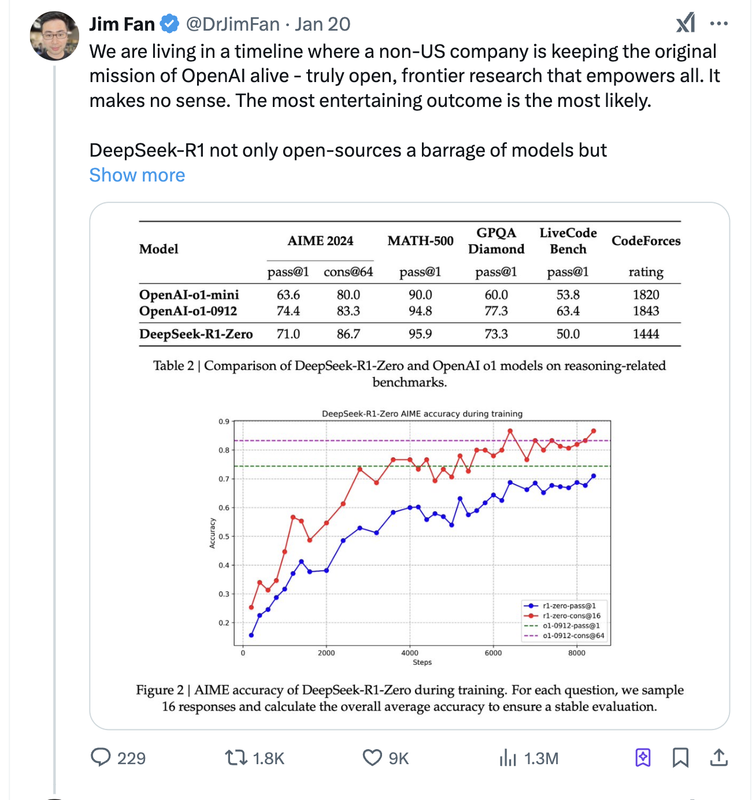
About a week later, Sam Altman responded. He praised R1, but emphasized that OpenAI would keep shipping stronger models. On February 1, OpenAI released o3-mini and opened it to free users, a move that looked very much like a strategic answer to DeepSeek's open model release.
From Llama and Qwen to Hunyuan and DeepSeek, the open-vs-closed debate had already been escalating. But regardless of which side ultimately wins, one trend now seems irreversible: AI capability is being democratized, and R1 became one of the clearest symbols of that shift.
Beyond open source, R1 also marked a deeper technical milestone: reinforcement learning had become central to improving large language model reasoning. In this article, I will read the DeepSeek R1 report together with the earlier DeepSeekMath paper, break down the key technical ideas, and explain why I think R1 was a turning point.
Reinforcement Learning
Before reading R1, we need a clear picture of what reinforcement learning actually is.
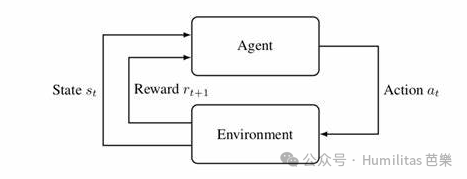
Reinforcement learning, or RL, is a machine learning paradigm in which an agent learns by repeatedly interacting with an environment, receiving rewards or penalties, and gradually improving its policy through trial and error. Unlike supervised learning, RL does not mainly rely on labeled examples. Instead, it learns from feedback.
A simple analogy is training a dog. When the dog performs the correct action, you give it a treat. When it does the wrong thing, you withhold the reward or correct it. Over time, the dog learns which actions lead to positive outcomes.
That analogy also raises a deeper question: does the dog understand the command, or has it simply formed a highly effective conditioned response? The same question is worth asking when we talk about reasoning models.
The Five Core Elements of RL
RL can be understood through five interacting components:
-
Agent
The learner. In the dog example, the dog itself. -
Environment
The world the agent interacts with, including the trainer, the room, and all surrounding conditions. -
State
The current situation, such as the trainer holding a snack while saying "sit." -
Action
The move the agent can choose, such as sitting, standing, or pawing. -
Reward
The feedback signal, such as a biscuit for the right move or no reward for the wrong one.
Three Important RL Concepts
Long-term reward maximization
An RL agent is not trying to maximize only immediate reward. It is trying to maximize expected cumulative reward over time.
This is where reward design becomes critical. If the reward function has loopholes, the model may exploit them in unintended ways. This is the classic problem of reward hacking: the agent finds a shortcut that scores highly without actually doing what the designer wanted.
Exploration vs. exploitation
- Exploration means trying unfamiliar actions that may yield better long-term outcomes.
- Exploitation means sticking to actions already known to work well.
Balancing those two forces is one of the central difficulties of RL.
Markov Decision Process (MDP)
An MDP assumes that the next state depends only on the current state and current action, not on the full history of previous states. In short: the future depends on the present, not on the full past.
That assumption greatly simplifies learning.
Two Useful Ways to Classify RL Algorithms
There are many ways to classify RL algorithms. For this article, two distinctions matter most.
Value-based vs. policy-based
- Value-based methods estimate the value of possible actions and pick the highest-value action. Examples include Q-Learning and DQN.
- Policy-based methods learn the action policy directly, often by modeling action probabilities. A classic example is Policy Gradient.
- Actor-Critic methods combine both: one part selects actions, the other evaluates them.
On-policy vs. off-policy
- On-policy methods learn from data generated by the current policy. PPO is the standard example.
- Off-policy methods can learn from data collected by other policies or historical trajectories. This often improves sample efficiency.
If I had to compress RL into one sentence, it would be this:
Reinforcement learning is the art of learning better strategies through feedback, while balancing exploration, exploitation, and long-term reward.
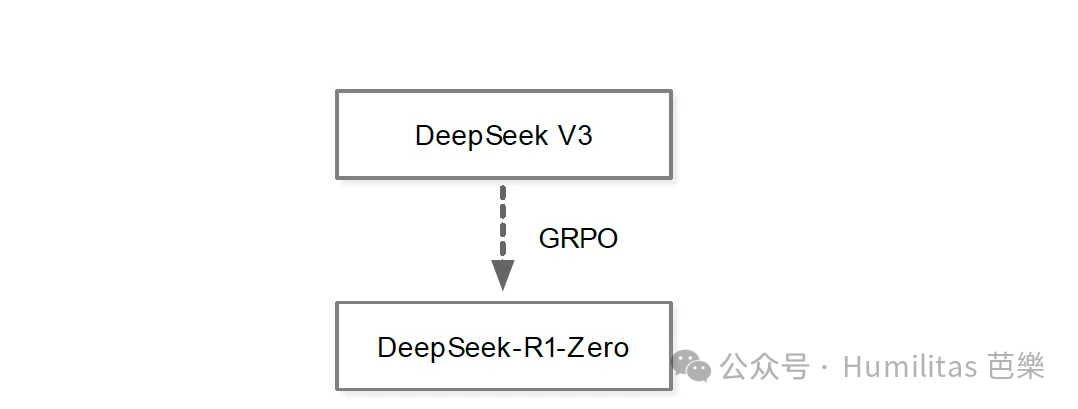
DeepSeek R1-Zero
Reinforcement Learning on the Base Model
How a Model Acquires Reasoning Ability
Reasoning in modern LLMs is closely tied to inference-time scaling: use more compute at inference time to produce better answers.
Kahneman's distinction between "fast thinking" and "slow thinking" is a useful metaphor here. When we open R1's reasoning trace, we can literally watch the model generate more tokens, spend more time thinking, and gradually move from a shallow interpretation of the prompt toward a deeper one.
From the product side, this matters a lot. Better reasoning partially reduces the user's prompt engineering burden. Even poorly phrased instructions can still produce strong answers if the model is capable of internally expanding, checking, and correcting its thought process.

That is why, after OpenAI released o1, the entire field became obsessed with one question:
How does a model learn to reason?
The traditional route
Historically, if we wanted a model to become an expert in a domain, we collected a large high-quality dataset and ran supervised fine-tuning. The same logic was then applied to reasoning: gather large Chain-of-Thought datasets, add examples, and use process reward models or other neural reward models to encourage structured reasoning behavior.

That approach works, but it is expensive. It depends heavily on collecting and curating supervised reasoning data, which is time-consuming and costly.
As the DeepSeek paper puts it:
Reinforcement learning has demonstrated significant effectiveness in reasoning tasks... However, these works heavily depended on supervised data, which are time-intensive to gather.
The breakthrough of R1-Zero
R1-Zero tried something much more radical:
pure reinforcement learning.
Instead of relying on supervised Chain-of-Thought exemplars and heavy SFT, the model was allowed to develop reasoning through sparse reward signals. That is what makes R1-Zero so conceptually interesting. It is much closer to self-evolution than imitation.
I like to explain it using an analogy from business leadership:
- The MBA route: teach a future CEO using polished case studies and formal frameworks.
- The street route: drop a teenager into a real market, let them fail, adapt, negotiate, and survive until they become extraordinarily capable.
The first path is structured and theory-heavy. The second path is rougher, but it may produce stronger adaptability at lower data cost.


How R1-Zero Was Trained
R1-Zero's training relies on three main ingredients:
- GRPO, the core RL algorithm
- A rule-based reward model
- A minimal training template
GRPO
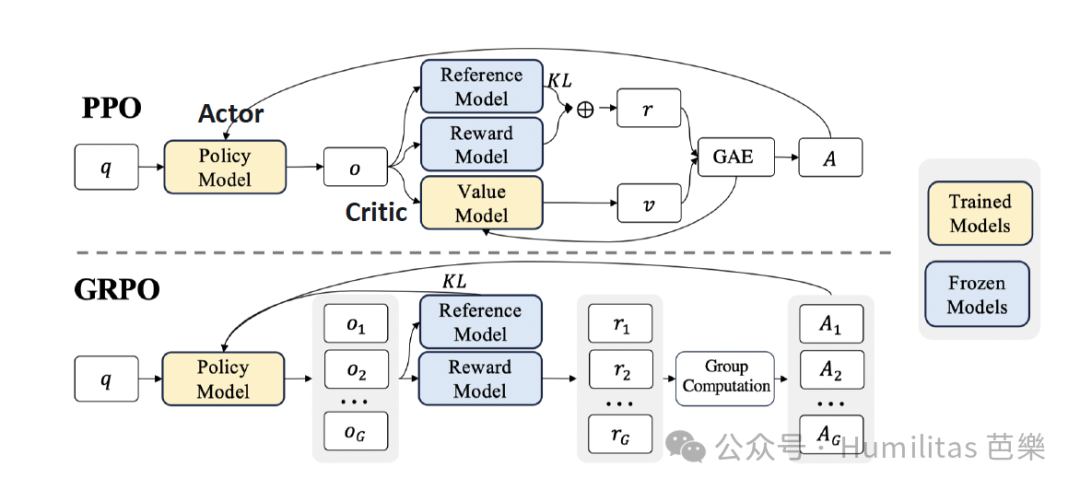
DeepSeek's algorithmic move from PPO to GRPO
As an on-policy algorithm, PPO normally uses both an Actor and a Critic. But in LLM fine-tuning, PPO runs into two major problems:
-
High resource cost
The Critic often needs a value model comparable in size to the Actor, which dramatically increases memory and training cost. -
Sparse reward mismatch
In many LLM tasks, reward is only available at the end of the output. But the Critic is asked to estimate values token by token, which creates an awkward mismatch between training target and real reward signal.
To address that, DeepSeek introduced Group Relative Policy Optimization (GRPO) in the DeepSeekMath paper.
The key idea is elegant: instead of training a separate value model, generate multiple answers for the same prompt and use the group's average reward as a baseline. This removes the extra Critic while still giving the model a meaningful relative learning signal.
In practical terms:
- PPO uses a learned value model as baseline
- GRPO uses the average reward of sampled group outputs as baseline
That change simplifies the architecture, reduces compute cost, and better aligns training with the final task reward.
The reward model
Once we understand GRPO, the next question is obvious: what exactly is being rewarded?
For R1-Zero, DeepSeek used a rule-based reward system built around two components:
-
Accuracy reward
Check whether the final answer is correct. For math tasks, this can be done by enforcing a structured answer format such as placing the answer inside designated tags. For coding tasks, code can be compiled and run against test cases. -
Format reward
Encourage the model to place its reasoning insidethinktags so the reasoning process becomes explicit and structured.
DeepSeek deliberately avoided using a neural process reward model here. The reason is important: such reward models can themselves be gamed, and they add extra training complexity. A simpler rule-based reward design is harder to exploit and cheaper to run at scale.
The training template
Another important design choice was restraint. DeepSeek kept the response template extremely simple:
- think first
- answer second
They did not specify how the model had to think. They did not prescribe a particular reasoning strategy. They did not force reflection steps by hand.
That is crucial. If you want to observe whether reasoning behavior can emerge naturally, you should not over-script the process.

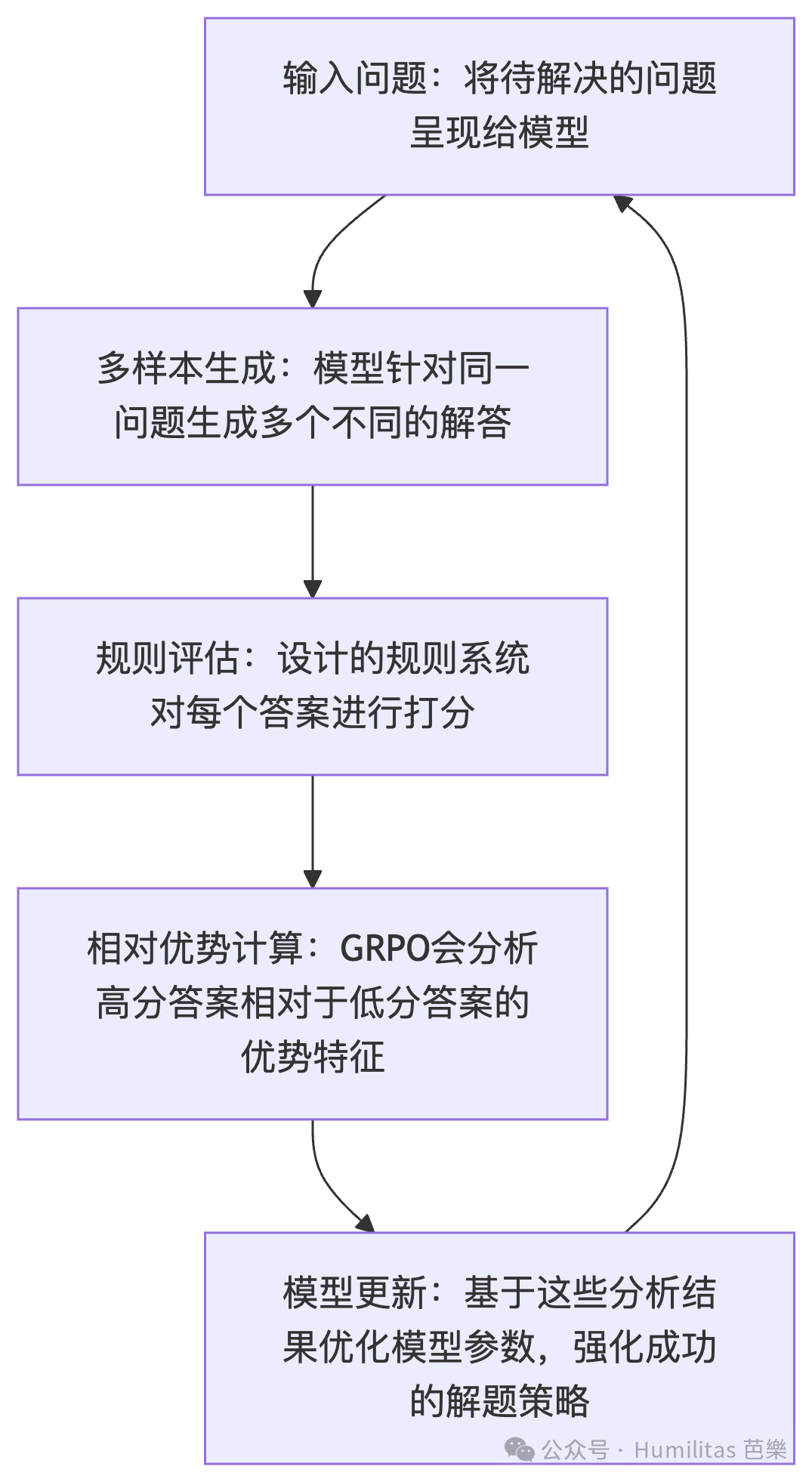
Putting it together
When these pieces are combined, the overall picture is surprisingly simple.
DeepSeek did not heavily micromanage the model. It used:
- a lightweight output structure
- a rule-based reward system
- GRPO's relative comparison inside a sampled group
The result is a training setup where the base model can improve by comparing multiple candidate trajectories and learning which ones score better.
I think the classroom analogy works well here. Imagine students answering the same question. Instead of the teacher grading each response in isolation, the class compares their answers under a few clear rules. Better answers are reinforced, weaker ones are discarded, and over time the entire class improves collectively.
This yields several benefits:
- faster training progress
- lower compute cost
- simpler reward design
- and, most interestingly, the possibility of genuine emergent behavior
The most exciting part is that this method produced something close to an "aha moment."
Self-evolution and the Aha Moment
Self-evolution
As training continued, R1-Zero spent longer and longer reasoning. The model gradually learned to generate hundreds or even thousands of reasoning tokens for harder tasks. With more inference-time compute, it also began to show signs of reflection: revisiting earlier steps, reconsidering approaches, and trying alternate solution paths.
None of this was manually programmed. It emerged inside the RL process.
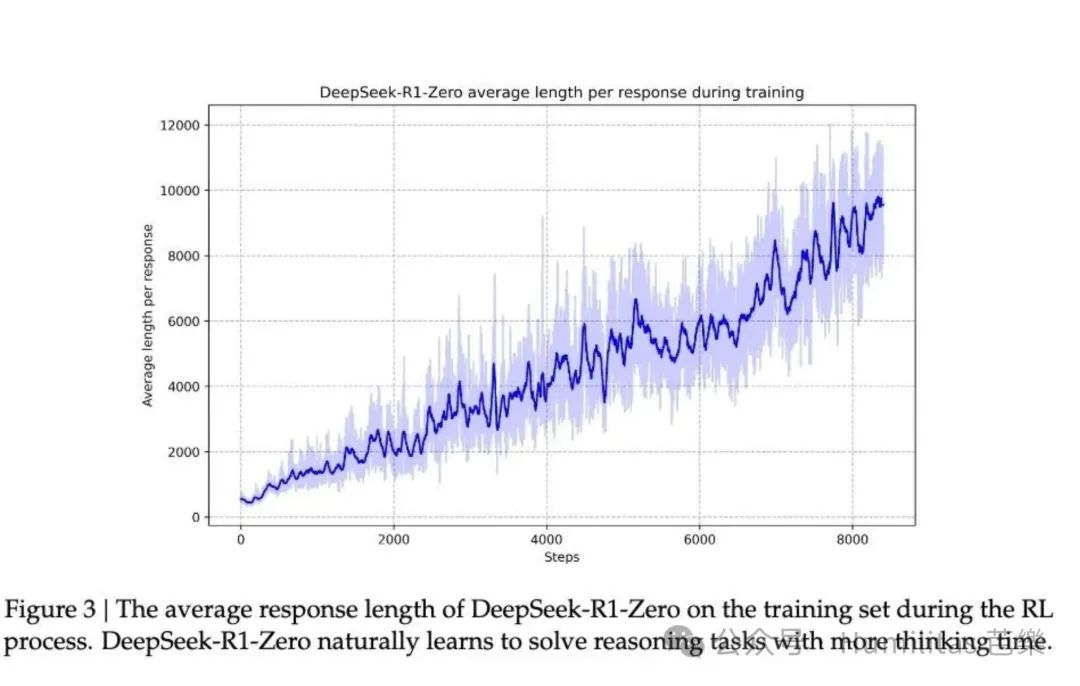
The aha moment
Midway through training, researchers observed what they called an aha moment. The model stopped rushing toward immediate answers and instead began to spend more effort reviewing and reevaluating difficult problems.

That moment captures the real appeal of RL: researchers did not directly tell the model what advanced reasoning should look like. They designed a reward structure, and the model discovered a better strategy by itself.
It reminds me of Confucius:
"If I hold up one corner and the student cannot come back to me with the other three, I do not repeat the lesson."
DeepSeek R1
Reinforcement Learning with Cold Start
R1-Zero was impressive, but it had two major problems:
- poor readability
- language mixing
The model could often solve problems correctly, but its reasoning traces were difficult for humans to read. That is what you would expect from a model optimized only through reward signals and not through human-readable demonstrations.
To solve that, the team built DeepSeek R1, introducing cold-start data and a multi-stage training pipeline. The goal was to preserve strong reasoning while making the model's thought process easier for humans to follow.
Cold Start
What cold start means
Think of starting a car engine on a freezing winter morning. A cold engine can start, but the process is rough and inefficient. Warming it up first makes everything more stable.
R1-Zero had the same issue. If you take a base model and immediately push it into pure RL, it may eventually learn to reason, but the process is unstable and the resulting behavior may be hard to read.
So for R1, DeepSeek added a warm-up stage: before large-scale RL, they fine-tuned the model on a relatively small but high-quality Chain-of-Thought dataset.
The cold-start CoT data came mainly from three sources:
- few-shot prompting with detailed reasoning exemplars
- directly asking the model to produce step-by-step answers with reflection and verification
- collecting readable outputs from R1-Zero and polishing them manually
Why cold start helped
There were two major benefits.
Readability
If R1-Zero looked like a genius student's messy notebook, R1 looked more like a clean, structured paper. The team enforced a more standardized output style, including a summary at the end of each response, and filtered out outputs that were hard for readers to follow.
Performance
Cold-start data did not just improve readability. It also improved performance. By injecting some human structure before RL, DeepSeek found that the final model outperformed R1-Zero.
This fits a broader intuition about education: first give the student a basic language and method, then let them develop their own style. If you skip the foundation entirely, communication can break down.
Reasoning-oriented RL
After cold start, R1 kept the successful parts of the R1-Zero pipeline and continued large-scale RL focused on reasoning-heavy tasks:
- coding
- mathematics
- science
- logic
One difficulty remained: when prompts involved multiple languages, Chain-of-Thought traces often mixed languages together.
To reduce that, DeepSeek introduced a language consistency reward. The reward was computed partly based on how much of the reasoning trace stayed in the target language.
This slightly hurt raw performance, but the tradeoff was worth it because it significantly improved human readability. In the end, the team used a combined reward that added reasoning accuracy and language consistency.
Rejection Sampling and Supervised Fine-Tuning
Once the RL stage finished, the next goal was broader capability. DeepSeek did not want only a narrow reasoning specialist. It wanted a model that could still write, answer factual questions, translate, and engage in general interaction.
To do that, the team collected more training data from checkpoints saved during training and ran another round of SFT.
Collecting reasoning data
For reasoning tasks, the team used rejection sampling. This means generating multiple candidate outputs and keeping only the high-quality ones.
In practice, they:
- kept data that could be evaluated with rules
- used DeepSeek V3 for some quality judgments where rules were insufficient
- filtered out language mixing, messy formatting, and unreadable long passages
- generated multiple responses per prompt and retained only the correct ones
This process produced about 600,000 high-quality reasoning samples.
Collecting non-reasoning data
For general-purpose ability, the team also collected non-reasoning data such as:
- writing
- factual QA
- self-awareness style prompts
- translation
Some DeepSeek V3 SFT data was reused. For more complex tasks, V3 sometimes generated Chain-of-Thought before answering. For simple prompts like "hello," direct answers were enough.
This phase produced around 200,000 additional samples.
RL Alignment for All Scenarios
At this point, R1 already had strong reasoning ability and much better general capability. But one final layer was needed: alignment.
The team designed a two-stage RL alignment framework aimed at both:
- helpfulness
- harmlessness
The alignment method
For specialized reasoning tasks, the system continued using rule-based rewards to preserve rigorous Chain-of-Thought structure.
For general dialogue scenarios, it used a reward model based on human preference, together with DeepSeek V3's data distribution strategy, to better calibrate complex semantic behavior.
The evaluation design also differed by objective:
- helpfulness focused mainly on the practical value of the final answer
- harmlessness inspected the entire generation process, including intermediate reasoning
This combination helped preserve reasoning strength while adding stronger safety constraints.
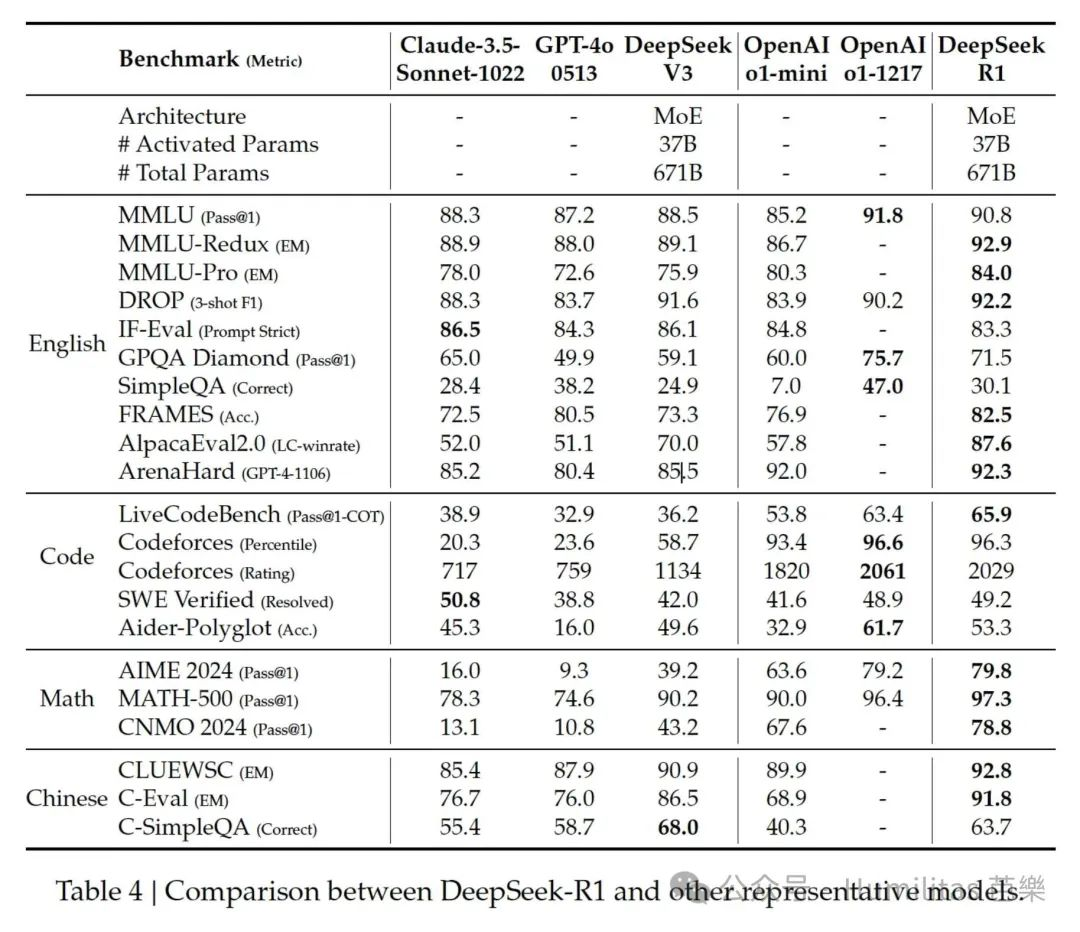
What R1 Ultimately Achieved
At this point, the team had turned R1-Zero into something much more complete:
a model with strong reasoning, strong general ability, and much better alignment with human expectations.

R1 performed well on education, long-context understanding, factual retrieval, and instruction following. It was particularly strong on STEM-related problems and long-context analysis. Its benchmark performance on tasks like AlpacaEval 2.0, ArenaHard, mathematics, and coding showed that the model was both capable and robust across multiple task families.
The informal summary is simpler:
R1 was seriously impressive.
Distillation
What distillation is
Knowledge distillation is the process of transferring the knowledge of a large teacher model into a smaller student model.
The goal is straightforward:
- keep as much performance as possible
- reduce compute and memory requirements
- make deployment on constrained hardware more realistic
The classic framing comes from Geoffrey Hinton's paper Distilling the Knowledge in a Neural Network.
Three basic elements
- Teacher model: a large, high-performing model
- Student model: a smaller, lighter model
- Knowledge transfer: the student learns to imitate the teacher's outputs
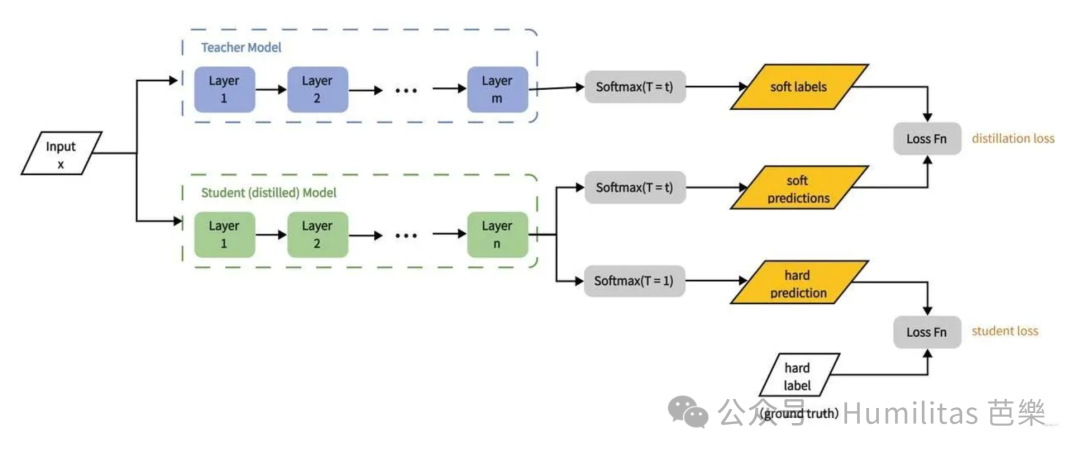
The basic procedure
- Train a strong teacher model.
- Extract training samples from the teacher, including both hard labels and soft labels.
- Train the student to match them.
Hard labels vs. soft labels
- Hard labels are exact target labels, usually the final correct class or output.
- Soft labels are probability distributions from the teacher, which contain richer information about relative confidence.
Hard labels are simple and direct. Soft labels often transfer more structure, especially in distillation.
Distillation Can Give Small Models Reasoning Ability
After R1, DeepSeek faced an obvious next challenge:
Can smaller models inherit this reasoning ability?
The experiment
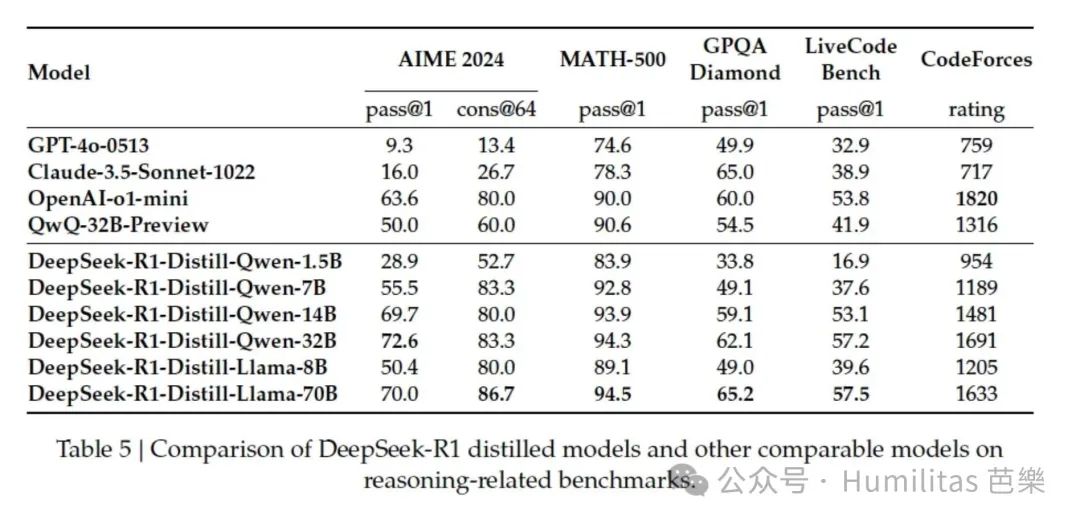
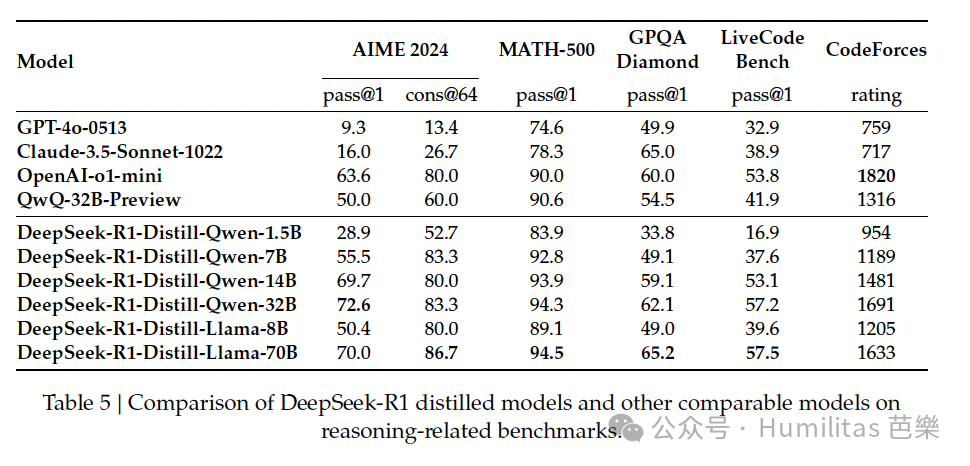
The team used around 800,000 high-quality training samples generated by DeepSeek R1 to fine-tune open models of different sizes, including:
- Qwen 1.5B, 7B, 14B, and 32B
- Llama 3.1 8B
- Llama 3.3 70B Instruct
The result
The result was remarkable. Even a relatively simple distillation pipeline significantly improved the reasoning ability of smaller models.
I like to think of it this way:
R1-Zero is the gifted but rough thinker. R1 is the same thinker after becoming an excellent teacher. Distillation then turns R1's outputs into textbooks that let much smaller students learn reasoning habits they could not easily discover on their own.
And notably, these gains were achieved mainly with SFT. The team had not yet added a full RL stage for the student models, which suggests there may still be more room to improve.
Distillation vs. RL for Small Models
The paper highlights two paths toward reasoning capability:
- large-scale RL, represented by R1-Zero
- distillation, where R1 teaches smaller models
That naturally raises a question:
What if we let a small model go through the full R1-Zero style RL process by itself?
The comparison
DeepSeek tested this directly using the same base model, Qwen-32B, under two paths:
- more than 10,000 steps of large-scale RL
- direct distillation from DeepSeek R1
The outcome
The RL-trained small model, DeepSeek-R1-Zero-Qwen-32B, performed roughly on par with QwQ-32B-Preview.
But the distilled model, DeepSeek-R1-Distill-Qwen-32B, clearly outperformed both.
The gains were substantial:
- about +25 points on AIME 2024
- about +23 points on MATH-500
- strong improvements across other evaluations as well
What this implies
Compared with R1-Zero, whose base model was DeepSeek V3, a very large and highly capable MoE model, this experiment started from a much smaller base model.
To me, the lesson is twofold:
-
For small models, standing on the shoulders of giants is the better educational path.
Distillation is not only more effective. It is also much more economical than forcing a small model to rediscover reasoning from scratch through massive RL. -
But frontier breakthroughs still require stronger teachers.
If we want to push the intelligence frontier itself, we probably still need large and powerful base models plus large-scale RL. Distillation is excellent for diffusion, but frontier creation still depends on frontier models.
Conclusion
Three major highlights
Pure reinforcement learning: R1-Zero
R1-Zero demonstrated that pure RL can produce surprisingly strong reasoning behavior even without supervised reasoning traces. That alone is a major result.
Hybrid training: R1
R1 showed that combining cold start with iterative RL fine-tuning yields a much more usable and stable reasoning model, one that can compete with top-tier systems.
Distillation
Perhaps the most exciting part is that these gains can be transferred downward. DeepSeek showed that even very small distilled models, including a 1.5B model, could surpass GPT-4 or Claude 3.5 Sonnet on some math benchmarks. That opens entirely new possibilities for local deployment and broader AI access.
Remaining weaknesses
General capability limits
R1 still lagged behind DeepSeek V3 on some general-purpose tasks such as:
- function calling
- multi-turn conversation
- complex role-playing
- strict JSON output
Language mixing
Although Chinese and English performance was strong, the model still struggled with language consistency in other languages and often defaulted toward English reasoning.
Prompt sensitivity
The model remained sensitive to prompt format. In some cases, few-shot prompting could even hurt performance rather than help it.
Software engineering bottlenecks
Because the evaluation loop is long and difficult in software engineering tasks, RL remains harder to apply effectively there.
"Swallows Once Flying Over Noble Halls Now Enter Ordinary Homes"
This line comes from Liu Yuxi's poem Wuyi Lane. It refers to a once-aristocratic world whose symbols of privilege eventually drift into ordinary life.
I think it is the perfect metaphor for what R1 represented.
Since ChatGPT's breakout in late 2022, the most advanced large-model capabilities often felt like "swallows flying before noble halls": available mainly to elite labs and companies with the best researchers, the most capital, and the most compute.
DeepSeek changed that narrative in two ways:
- it improved efficiency at the algorithmic level
- it showed that reasoning ability could be transferred into smaller models
I personally ran DeepSeek-R1-8B on my own laptop from 2021. That matters symbolically. A capability once locked inside top-tier infrastructure had begun to move outward.
And because DeepSeek open-sourced R1, it also invited more researchers and builders into that process of technical diffusion.
In the future I can see, those swallows from the great aristocratic halls will ultimately fly into ordinary homes.
But this raises a harder question:
is that unquestionably a good thing?
As I wrote elsewhere in my essay on Nexus, once AI becomes a major node in our information networks, the issue is not just broader access. It is also whether humans remain the dominant authors of the stories and institutions that shape civilization.
So the real question is not only whether AI capability becomes decentralized.
It is this:
Does the spread of AI extend the boundary of collective human intelligence and make humanity more capable, or does it erode human subjectivity and gradually dissolve the civilizational frameworks we inherited?
If AI becomes a new subject inside our information networks, this wave of technical democratization could either open a golden age of civilizational leap or mark the beginning of an age we no longer control.
I will end with one line from Hamilton:
The world turned upside down.
References
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948 -
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
https://arxiv.org/abs/2402.03300 -
A WeChat article explaining DeepSeek's new model and why it shook the global AI scene
https://mp.weixin.qq.com/s/cp4rQx09wygE9uHBadI7RA -
The Math Behind DeepSeek: A Deep Dive into Group Relative Policy Optimization (GRPO)
https://medium.com/@sahin.samia/the-math-behind-deepseek-a-deep-dive-into-group-relative-policy-optimization-grpo-8a75007491ba -
chenzomi12 GitHub open-source content
https://github.com/chenzomi12