Do You Really Understand LLMs? A Deep Dive into Transformer
Introduction
At the beginning of 2025, AI was moving fast again. DeepSeek shocked the industry with its reasoning performance, OpenAI kept extending the GPT family, and Claude continued to win users through careful language understanding. The models looked different on the surface, but they all still rested on the same architectural foundation:
Transformer.
Since 2017, Transformer has become the core backbone of modern language models. Whether a model writes code, answers questions, generates charts, or carries on natural dialogue, its capabilities are built on a mechanism introduced by Transformer: self-attention.
That mechanism gave models a way to capture long-range dependencies and understand relationships between tokens inside a sequence. It is the reason modern LLMs can produce fluent and coherent outputs at all.
Many people use these systems every day, but relatively few can explain how they work under the hood. Transformer often feels like a black box, even to many people already working in AI. In this article, I want to unpack that box step by step and explain the architecture from first principles.

Two notes before we start:
- This article is mainly my own synthesis after studying the references listed at the end.
- You do not need advanced mathematics, but high-school-level linear algebra intuition will help.
Encoding and Decoding
To understand Transformer, we first need to understand what "encoding" and "decoding" actually mean.
What does "code" mean in language?
In natural language processing, a "code" is simply a representation of meaning in a form a machine can manipulate.
Human language itself is already a kind of encoding. Different languages use different symbols, sounds, and grammar to refer to the same underlying objects or ideas. Translation works only because different languages can still point to the same semantic referent.
Imagine someone pointing at an apple. The object is the same, but the English code is "apple" and the Mandarin code is "pingguo." The surface form changes, but the semantic referent is shared.
Context matters as well. The word "apple" could mean:
- a fruit, in the context of bananas, pears, vitamins, and a grocery store
- a company, in the context of laptops, phones, Jobs, and software
So when we talk about code in language models, we are really talking about a way to preserve semantic structure while abstracting away from surface form.
Turning semantics into numbers
To let a machine process language, we need a numerical representation that satisfies two conditions:
- it can be computed efficiently
- it preserves semantic relationships
Two simple representations appear early in the story:
Token IDs
A tokenizer splits text into tokens and assigns each token an integer ID.
For example:
"I love machine learning" -> [101, 1045, 2293, 3698, 4083, 102]
This is useful for indexing, but the numbers themselves carry no semantic geometry. Similar words do not get nearby IDs.
One-hot vectors
A one-hot vector represents each token as a vector whose length equals the vocabulary size. Only one position is 1; all others are 0.
"cat" -> [0, 1, 0, 0, ...] "dog" -> [0, 0, 1, 0, ...]
This is better than raw IDs in one sense: it is vectorized. But it is still extremely sparse and semantically weak. Every token is equally distant from every other token.
That is the core limitation of both token IDs and one-hot encodings:
neither gives us a good representation of relative semantic similarity.
Latent space
The ideal solution lies between those two extremes. We want a dense vector space with manageable dimensionality, where semantic similarity is reflected geometrically.
That space is what we usually call latent space.
In latent space:
- semantically related words are close together
- semantically unrelated words are far apart
- algebraic relationships can begin to emerge
Classic examples look like this:
vector("king") - vector("man") + vector("woman") ~= vector("queen") vector("China") - vector("Beijing") ~= vector("France") - vector("Paris")
This kind of representation solves the sparsity problem of one-hot encoding while preserving semantic structure.
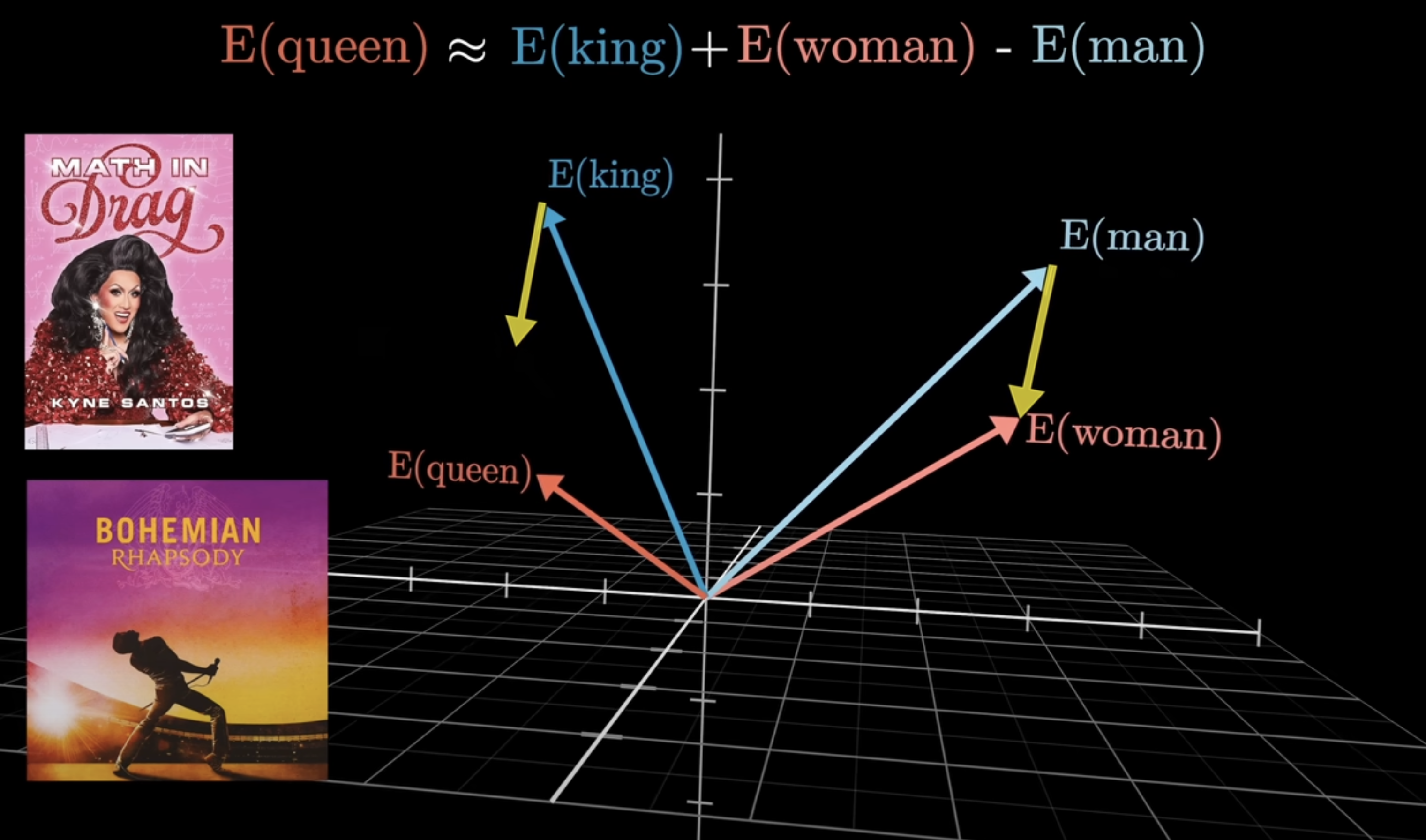
At a high level, moving from token IDs or one-hot vectors into latent space is a kind of space transformation. That leads directly to matrices.
Matrices and Space Transformation
What a matrix really does
A matrix is not just a rectangular table of numbers. In this context, it is best understood as a rule for transforming one vector space into another.
If a matrix maps an M-dimensional space into an N-dimensional space, then:
- the input dimension tells us the structure of the original space
- the output dimension tells us the structure of the new space
This is why matrix multiplication matters so much in deep learning. It is how we change the coordinate system in which information is expressed.
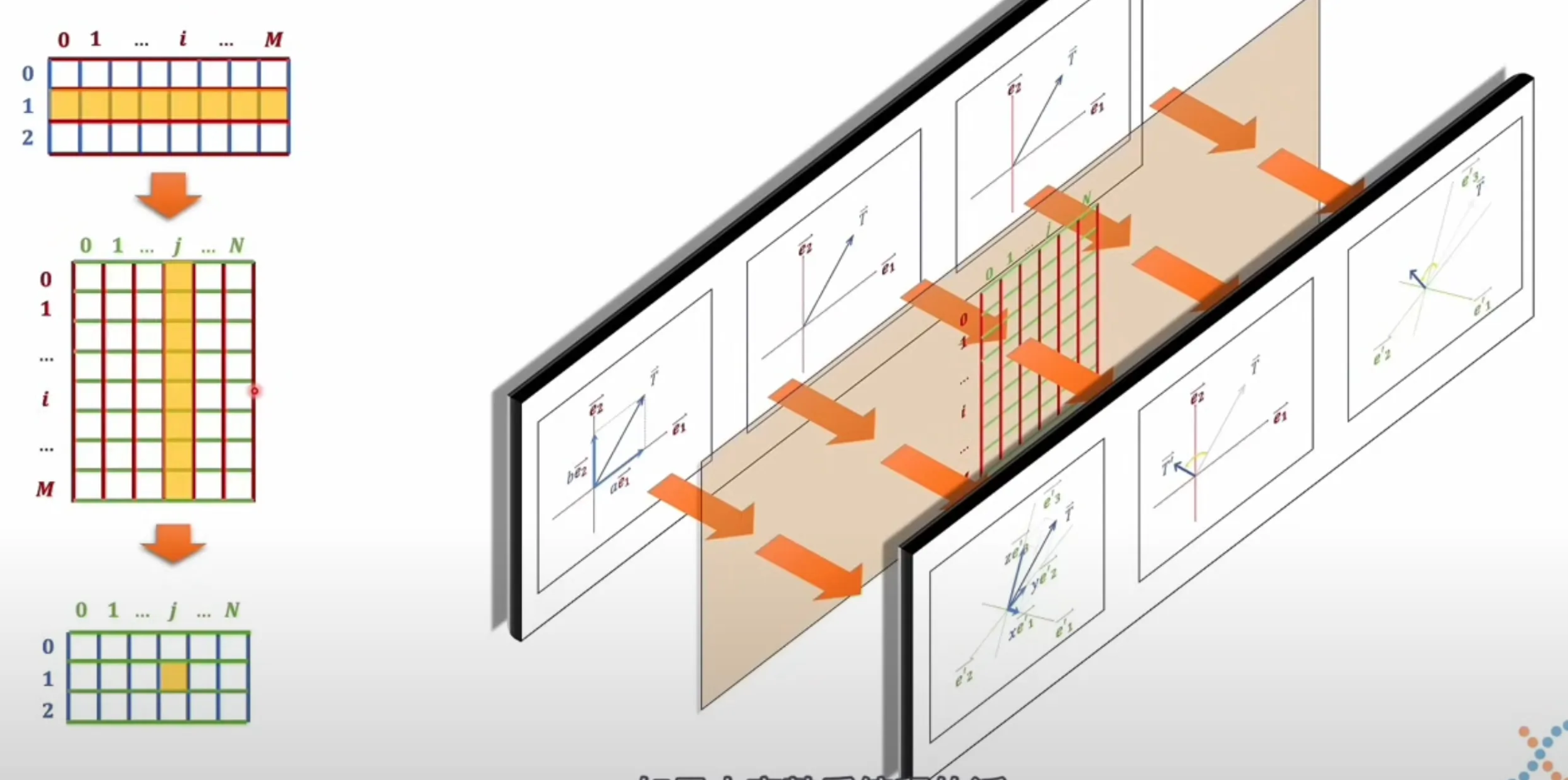
When a vector is multiplied by a matrix, the result is a linear transformation. In geometric terms, this means:
- the vector is re-expressed in a new space
- certain structural relationships are preserved
- the transformation is controlled by the matrix, not by the content of the vector itself
This is the key intuition we need for embeddings, QKV projections, feed-forward layers, and output projections. Transformer is full of matrix-defined space transformations.
Why this matters for language
Once language is represented as vectors, every major step in the model becomes a structured movement through different spaces:
- token space
- embedding space
- attention subspaces
- hidden representation space
- output distribution space
Transformer is not magic. It is a sequence of learned transformations between spaces that progressively re-express meaning.
Embeddings
How token embeddings work
Earlier we said that one-hot vectors are too sparse and too high-dimensional. Embedding solves this by learning a lower-dimensional dense representation.
If x is a one-hot vector and W is an embedding matrix, then the embedding is:
e = W^T x
Where:
xis the one-hot inputWis the embedding matrixeis the resulting dense vector
The embedding matrix has shape V x D, where:
Vis the vocabulary sizeDis the embedding dimension
Usually D is much smaller than V.

This is the first major learned projection into latent space.
What embeddings do
Embedding is the model's first attempt to turn surface symbols into semantic structure.
Its value lies in three things:
-
Dimensionality reduction
It compresses sparse symbolic input into dense numerical structure. -
Semantic organization
Similar tokens begin to live near one another in the learned space. -
Generalizability
The same idea can be applied outside language, for example to user IDs, item IDs, or graph nodes.
Word2Vec and its limits
Word2Vec was one of the most important early embedding methods. It taught us that a model could learn a semantic dictionary by training token vectors so that words with similar contexts land in nearby places.
That was a huge step. But Word2Vec still had major limitations:
- it modeled single-token semantics better than sentence-level meaning
- the embeddings were static
- the same word had the same vector in every context
That last point is decisive. The word "bank" in "river bank" and "investment bank" should not mean the same thing. Static embeddings cannot solve that. Transformer can.
Self-Attention
This is the real heart of the article.
Transformer works because it gives the model a way to understand not just the meaning of a token by itself, but the meaning of a token inside context.
Why attention is needed
Word embeddings solve objective lexical meaning, but human language is not built from isolated dictionary entries. Meaning changes with context.
Consider the following examples:
-
"Could I add you on WeChat, beautiful?"
Here "beautiful" functions as direct praise. -
"Excuse me, beautiful, could you move a little?"
Here "beautiful" is mostly a polite social address. -
"spicy food" vs. "a spicy personality"
The same word points to different properties in different contexts.

Static embeddings cannot capture this. They assign the same vector to the same token regardless of context.
Attention solves the problem by asking:
When I process this token, which other tokens in the sequence should I pay attention to in order to understand it correctly?
Traditional sequence models such as RNNs process information step by step. Transformer abandons that linear bottleneck and allows every token to interact directly with every other token.

The math of self-attention
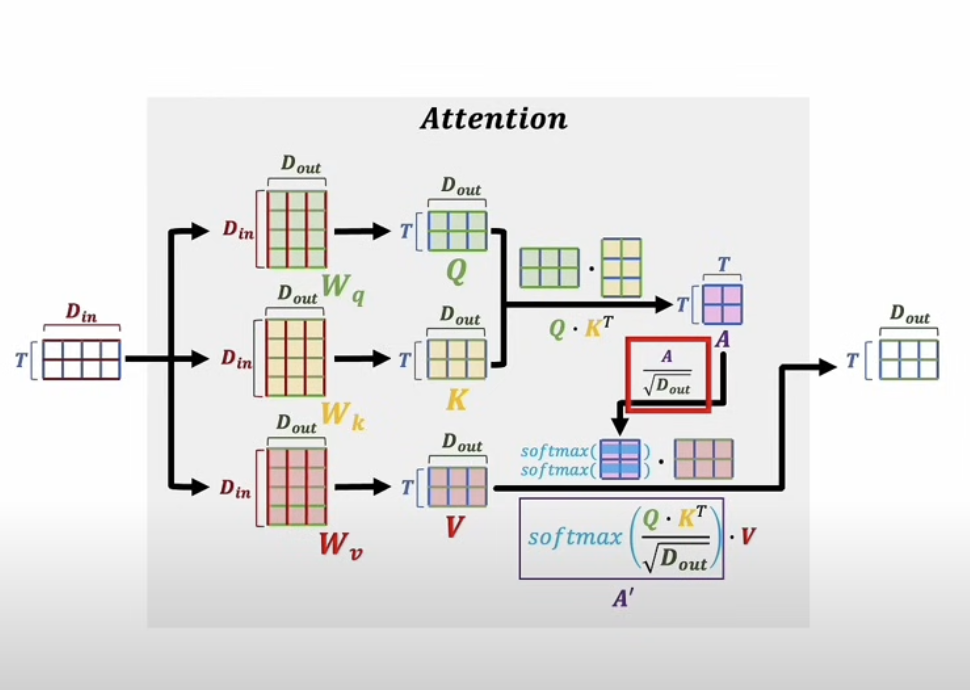
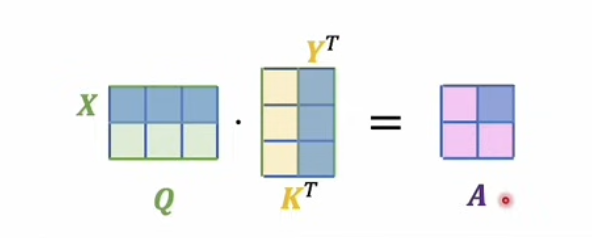
Suppose our embedded input sequence is represented by a matrix X, where each row is a token vector.
We project X into three different spaces:
Q = X W_Q K = X W_K V = X W_V
These stand for:
Q: QueryK: KeyV: Value
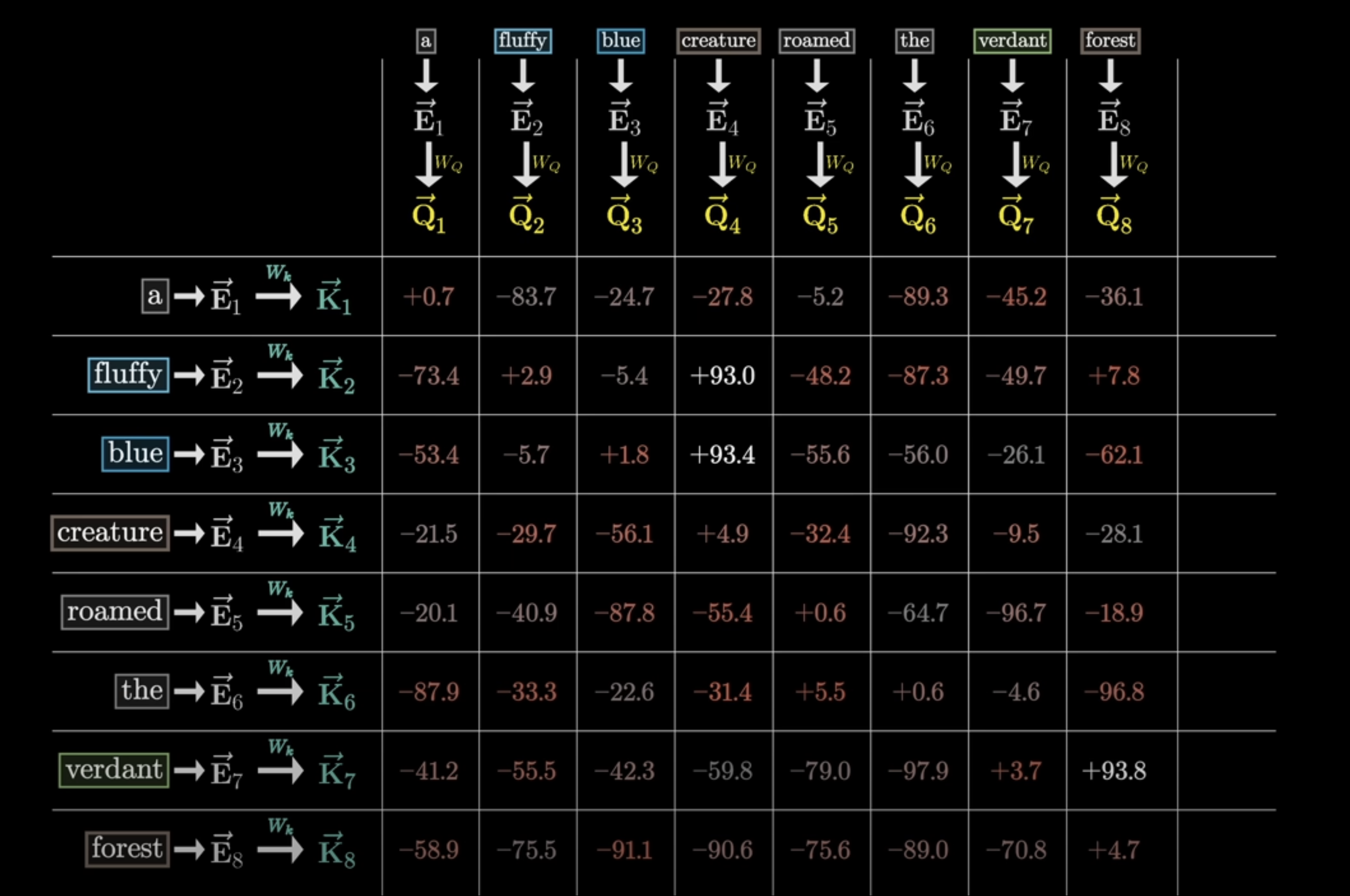
Next, we compute attention scores by multiplying queries and keys:
Scores = Q K^T
Then we scale the scores:
Scaled Scores = Q K^T / sqrt(d_k)
Then we normalize them with softmax:
A = softmax(Q K^T / sqrt(d_k))
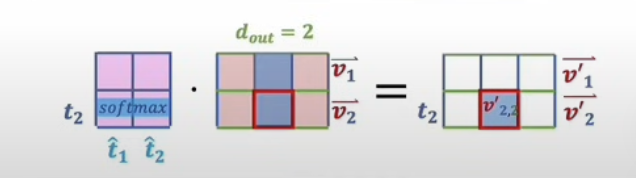
Finally, we use those attention weights to combine the values:
Output = A V
That gives us the famous formula:
Attention(Q, K, V) = softmax(Q K^T / sqrt(d_k)) V
What Q, K, and V really mean
The formulas look abstract, but the logic is simple.
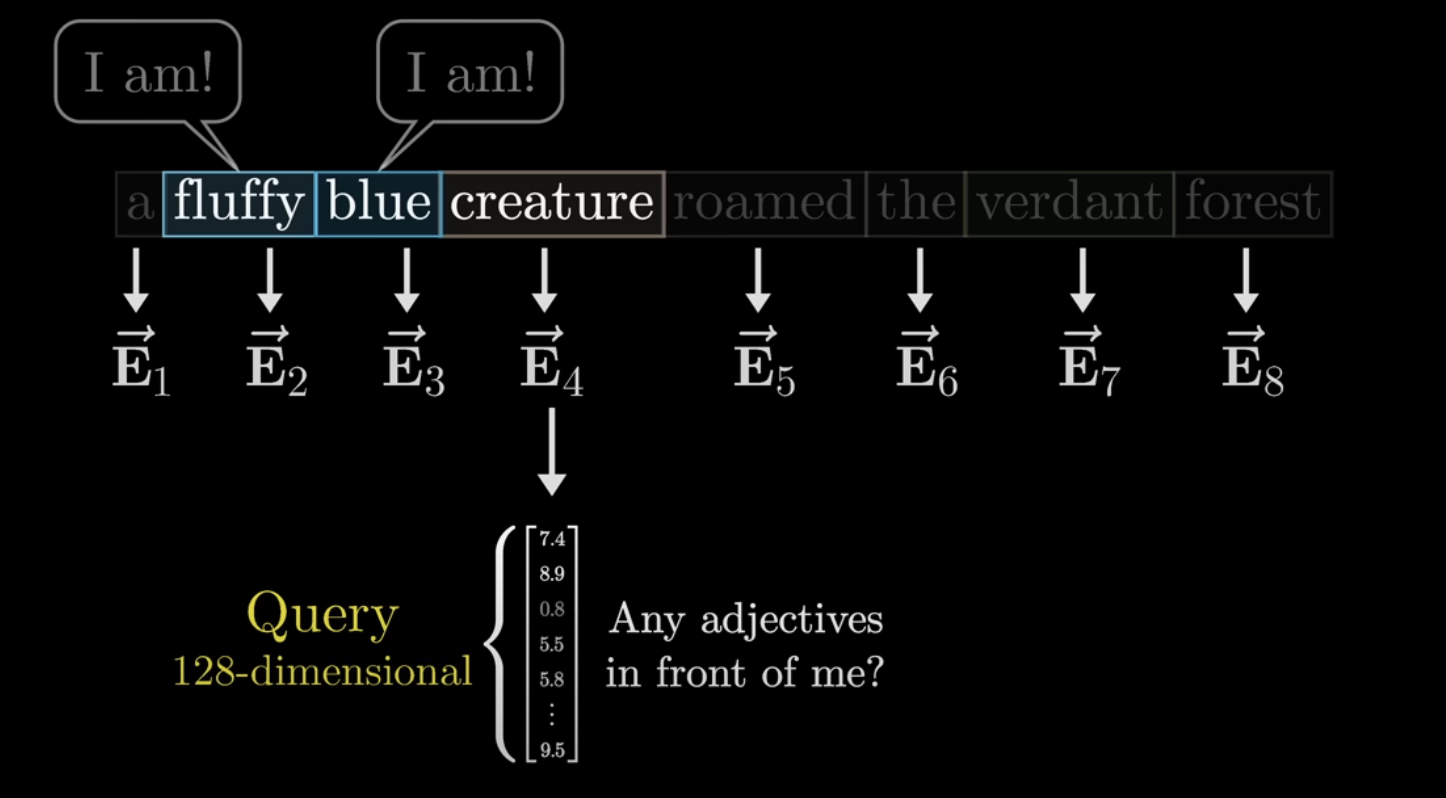
Query
Query is the current token asking:
Which other tokens are relevant to me right now?
It is an active search signal.
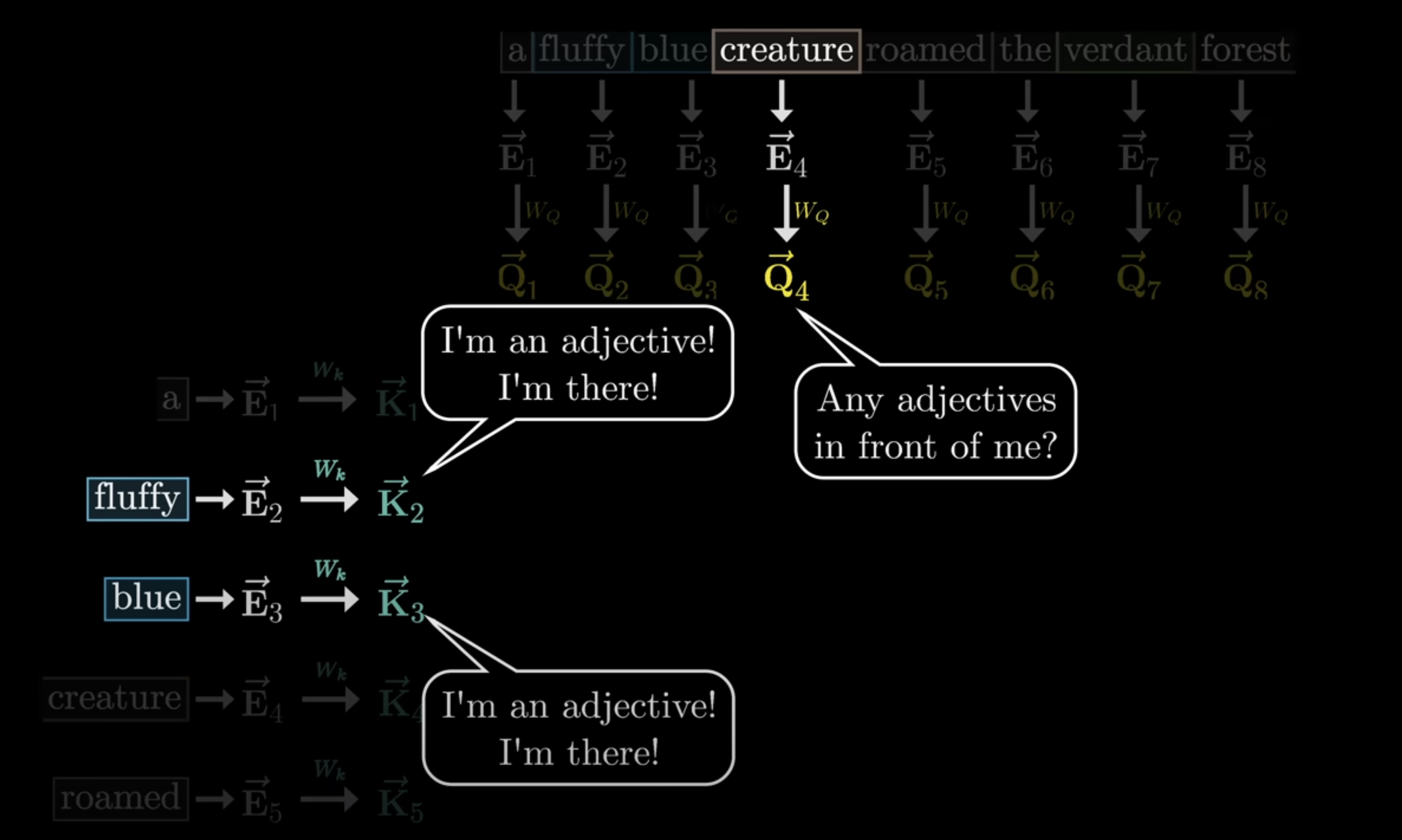
Key
Key is how each token advertises itself:
This is the kind of information I contain.
It acts like an index that other tokens can match against.
Value
Value is the actual information content that will be retrieved and aggregated.
If Query is the question and Key is the index, Value is the substance being pulled into the final contextual representation.
Q K^T
This computes relevance between every token and every other token. The result is a full relation map over the sequence.
Why divide by sqrt(d_k)?
Without scaling, large dot products would push softmax toward extreme distributions, making training unstable and gradients weaker. The scaling step keeps values in a healthier numerical range.
A V
This is where the contextual rewriting actually happens.
The V vectors hold the original token information. The attention matrix A tells us how context should modify or weight that information. The output is therefore not static lexical meaning, but context-sensitive meaning.
That is why the same token can mean different things in different sentences.
In plain English:
Vis the token's baseline semantic contentAis the context-dependent weighting patternA Vis the context-adjusted representation
That is the leap from objective lexical meaning to dynamic contextual meaning.
Positional Encoding
Self-attention has one major limitation:
by itself, it is position-agnostic.
If we shuffle the order of tokens, pure attention does not automatically know that the sequence changed. But in language, order matters:
- "the cat chased the dog" is not the same as "the dog chased the cat"
- changing word order can reverse meaning or create nonsense
So Transformer must inject positional information explicitly.
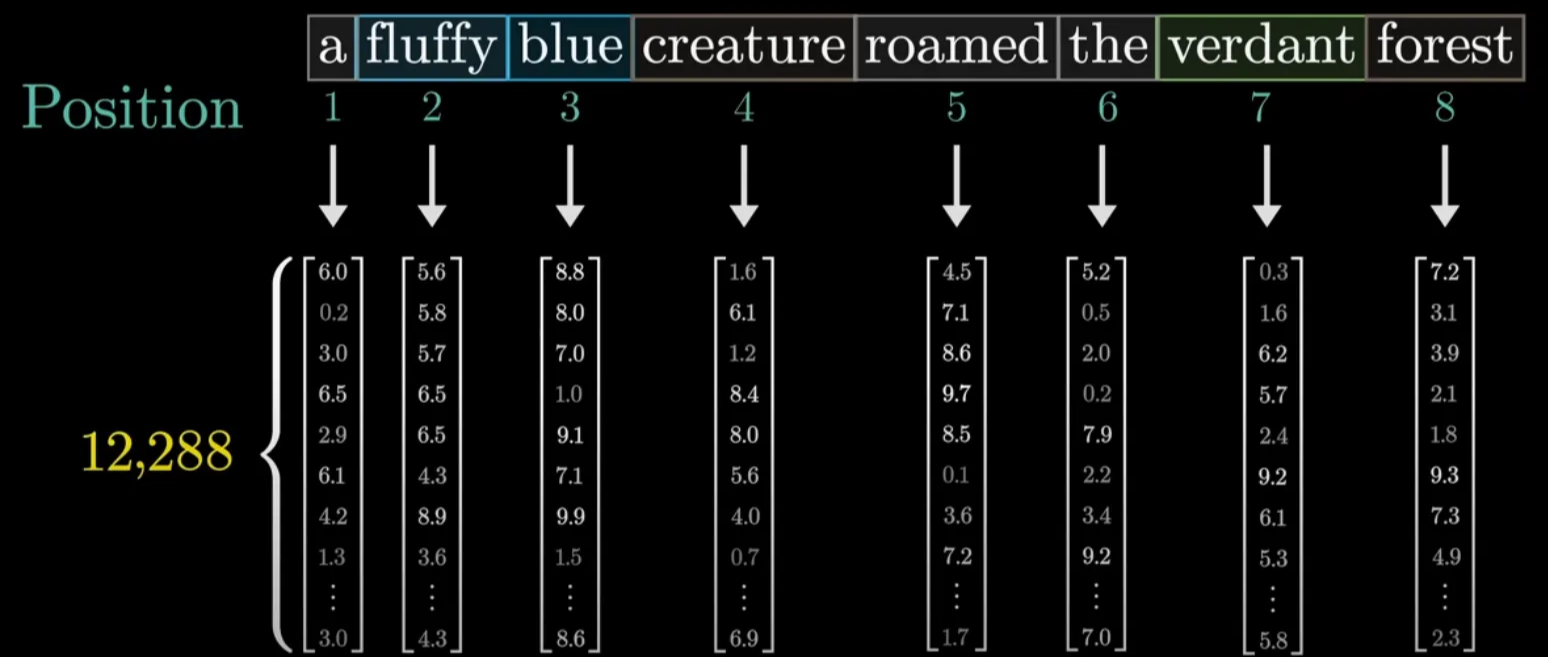
In the original paper, this was done with sinusoidal positional encoding:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
Where:
posis the token positioniis the dimension indexd_modelis the hidden size
This creates a unique position vector for each token position, which is then added to the token embedding:
Input Representation = Token Embedding + Positional Encoding
Now the model knows both what the token is and where it is.
Multi-Head Attention
Multi-head attention is one of Transformer’s other major innovations.
Instead of computing just one attention pattern, the model computes several in parallel. Each head has its own learned projections and can focus on different aspects of the sequence.
How it works
The process is:
- send the same input into multiple attention heads
- let each head compute its own attention output
- concatenate the results
- apply one final linear projection
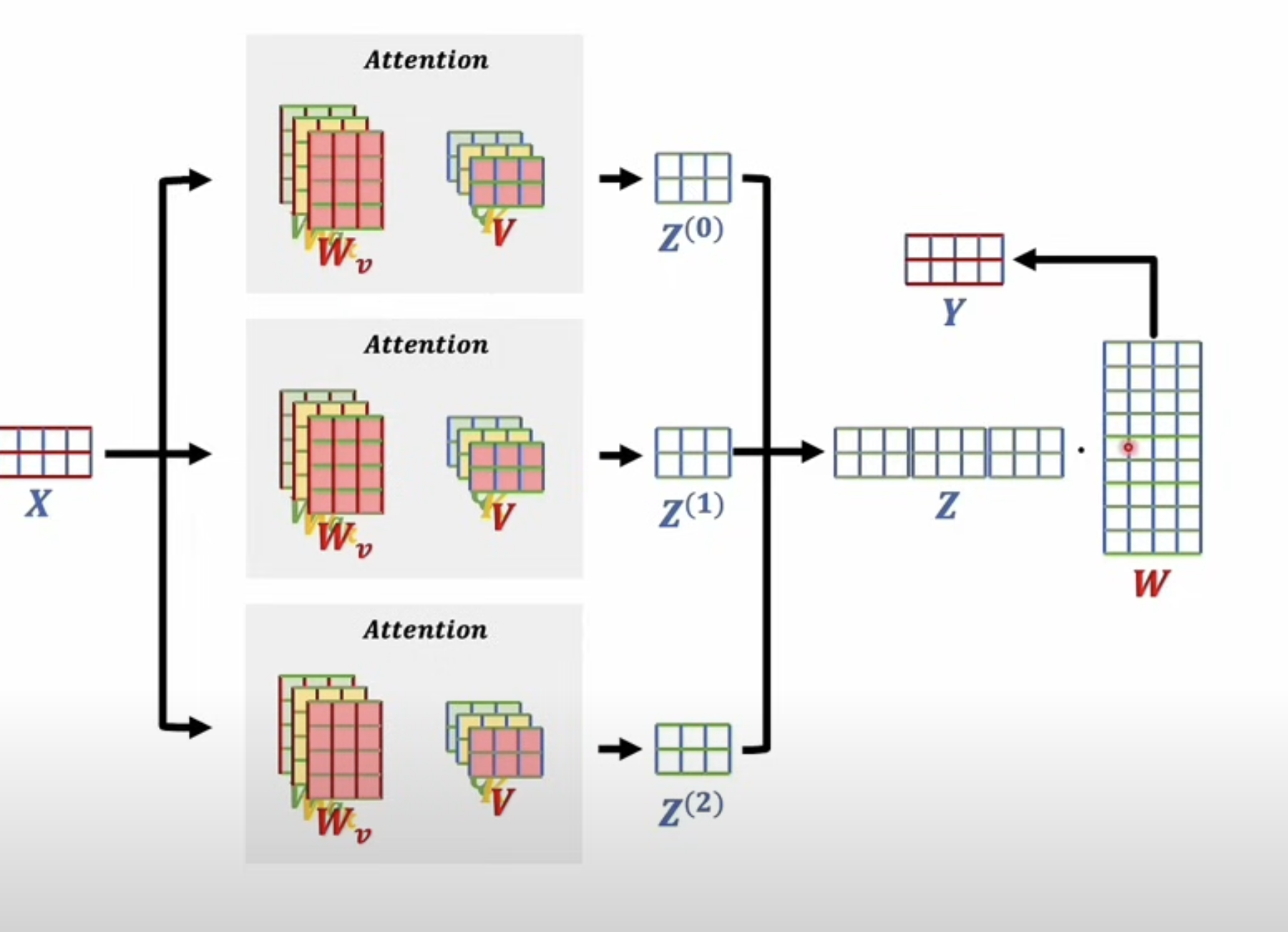
In the full paper version, each head has its own W^Q, W^K, and W^V, and all heads are later merged by an output matrix W^O.

Why multiple heads help
The core idea is diversity of representation.
Different heads can learn to focus on different patterns:
- syntactic structure
- long-range dependencies
- tense or aspect
- emphasis or sentiment
- pronoun resolution
If everything were forced through one single attention pattern, important subtle structures could be drowned out.
Multi-head attention gives the model multiple parallel views of the same sequence.

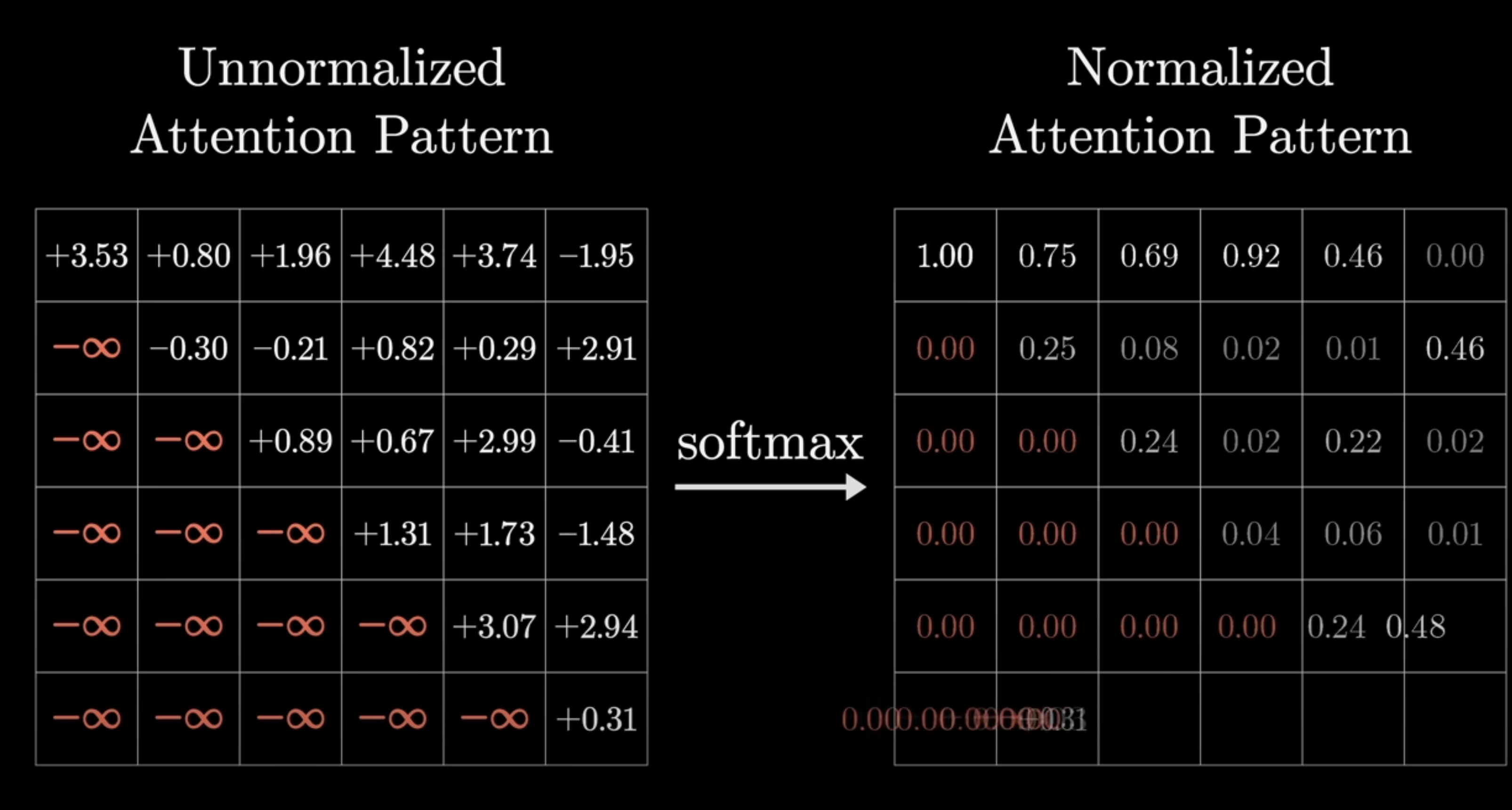
Masking
Masking is one of the less glamorous but absolutely necessary parts of Transformer.
Why masking is required
In autoregressive generation, when the model predicts token t, it must not be allowed to see tokens t+1, t+2, and so on.
But standard self-attention would let every position attend to all positions. That would allow the model to cheat during training by peeking into the future.
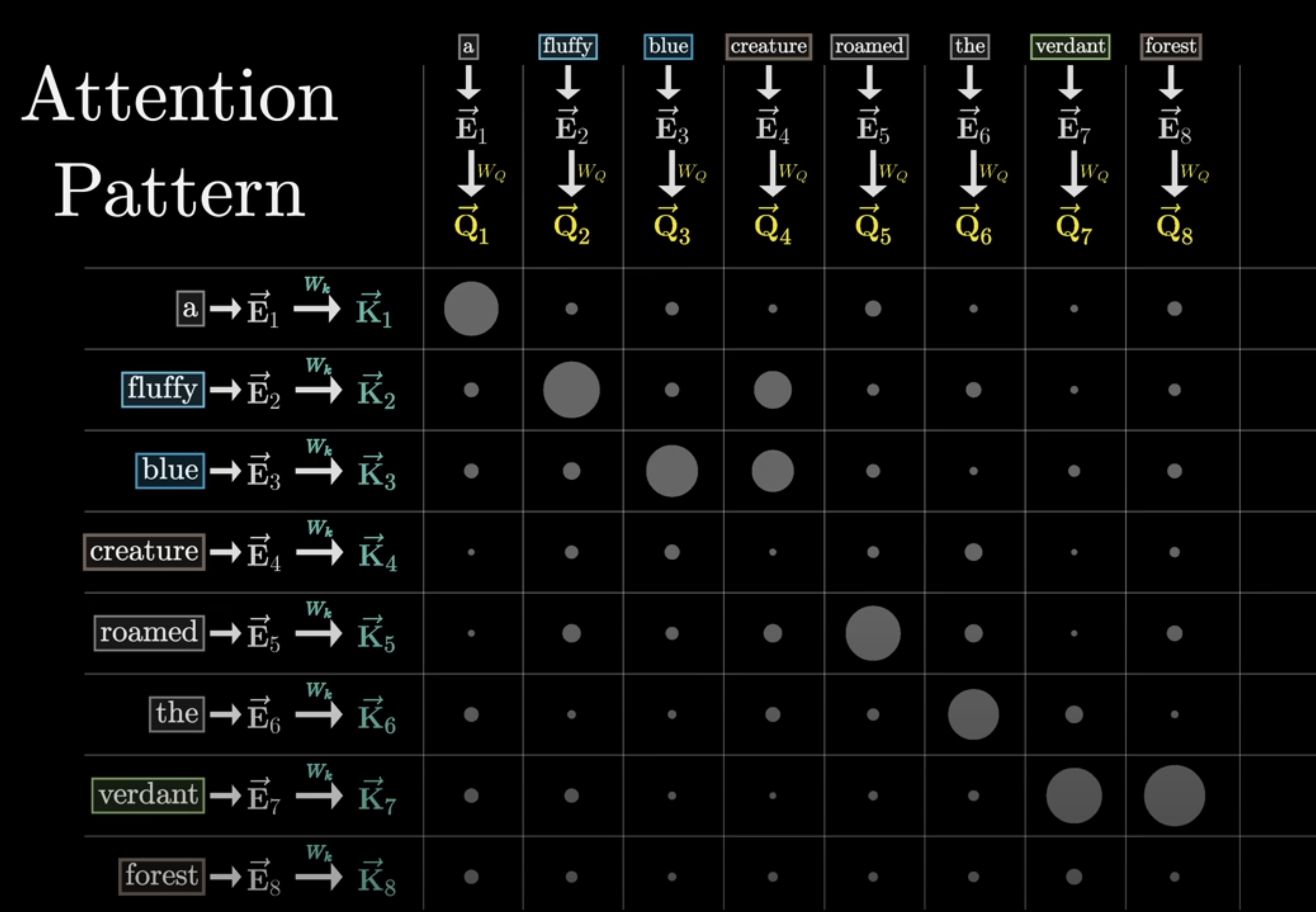
How masking works
After computing the score matrix Q K^T, but before applying softmax, we set all illegal future positions to negative infinity.
After softmax, those positions get probability zero.
So the model can only attend to past and current tokens.
Training and Inference
Transformer behaves differently during training and during generation.
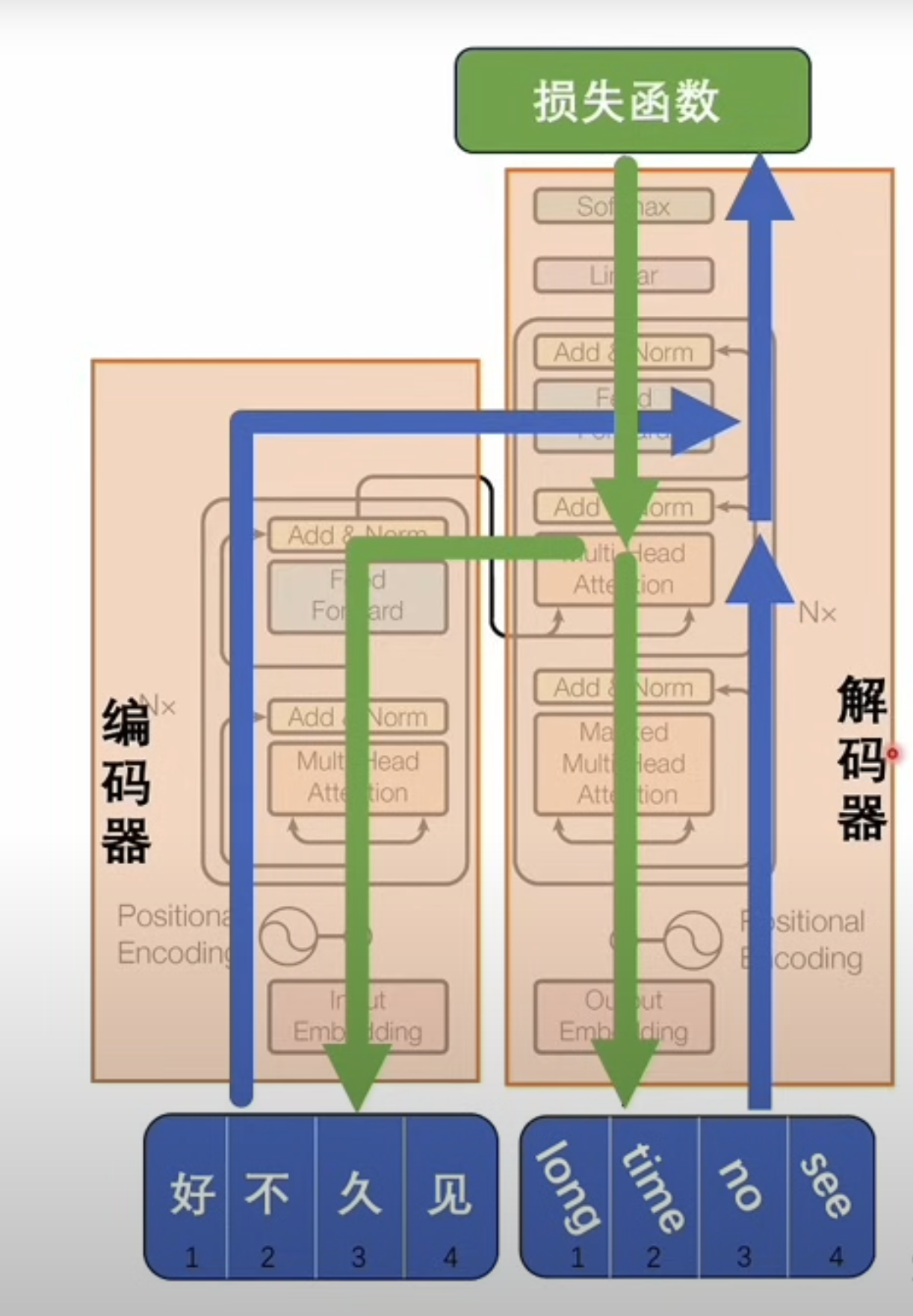
Training in the encoder-decoder setting
Consider a translation example: translating a short Mandarin phrase meaning "long time no see" into English.
During training:
- the source sentence is fed into the encoder
- the target sentence is fed into the decoder
- the decoder uses cross-attention to access encoder outputs
- the model predicts the next target token
- loss is computed against the true target sequence
- gradients update the parameters
The key objective is semantic alignment across languages: different surface forms should map to compatible latent representations when they express the same meaning.
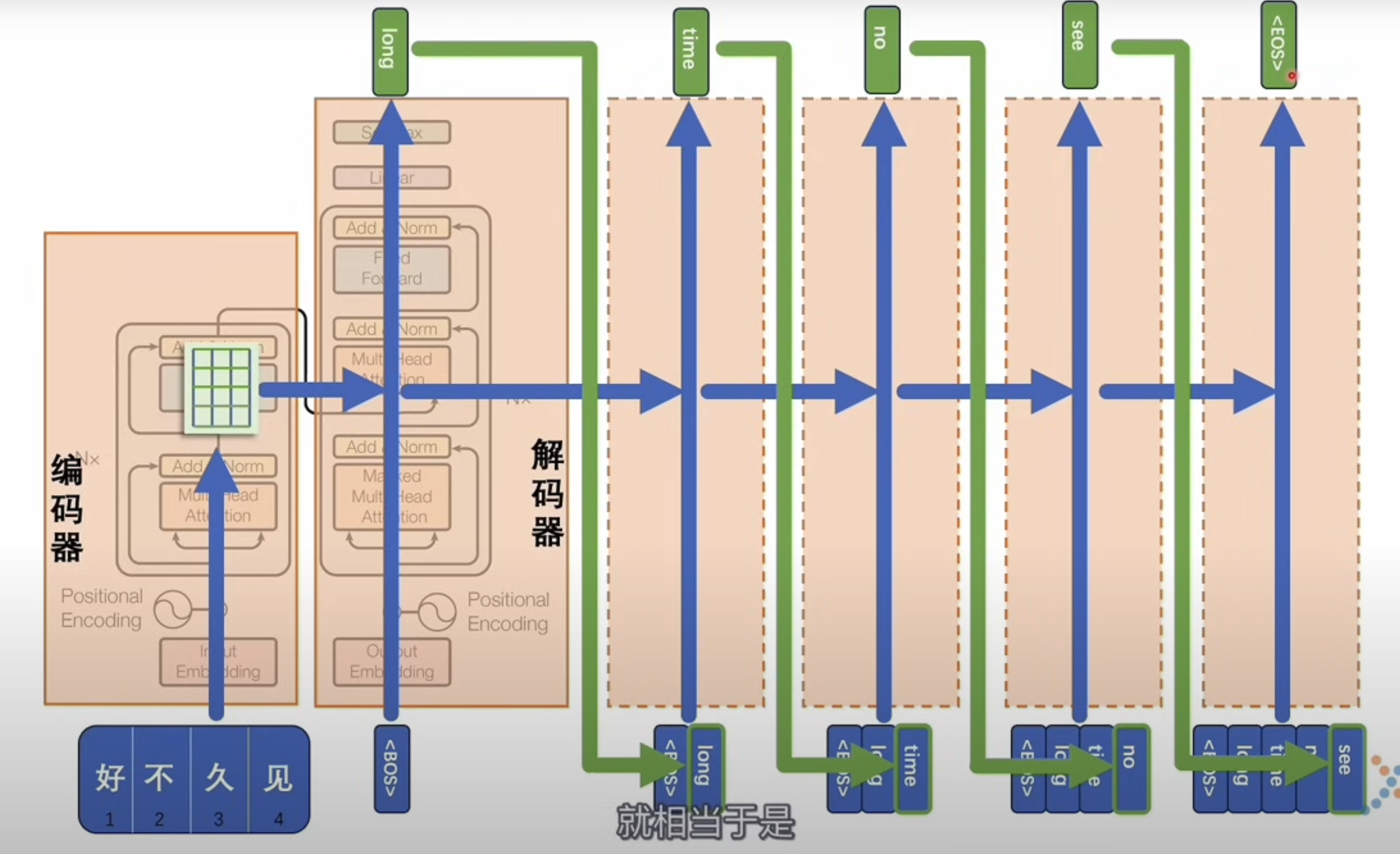
Generation at inference time
At inference time, we do not already know the full target sequence.
So decoding becomes autoregressive:
- encode the source sentence
- start the decoder with a special start token
- predict the next token
- append that predicted token
- repeat until an end token is produced
This solves the sequence-to-sequence length mismatch problem. The output can be any length.
Why the decoder does both encoding and decoding
The decoder is not merely "decoding" in the everyday sense. It also encodes the already generated target-side context into latent representations, then uses those representations to predict the next token.
That is one reason decoder-only models such as GPT can work so well. They treat the prompt as already-generated context and continue generating from there.
Decoder-only models
A decoder-only model has no separate encoder, but it can still do translation, summarization, and many other tasks because pretraining teaches it to operate in a shared token space across many tasks and languages.
When you prompt it with:
Translate into English: a common Mandarin phrase meaning "long time no see"
the model treats that as context and continues the sequence in a way learned during training. It does not need a separate encoder-decoder structure to do so.
Closing
Transformer gave us a radically new mathematical way to understand language.
We saw:
- how discrete symbols become vectors
- how vectors enter latent space
- how self-attention constructs contextual meaning
- how position is reintroduced
- how multiple heads create parallel semantic views
- how masking preserves causality
- and how decoding turns representations into generation
The most important intellectual shift, in my view, is the movement from static word meaning to dynamic contextual meaning.
Word2Vec gave us a semantic dictionary. Transformer gave us a mechanism for rewriting meaning as context changes.
That leads to the deepest question of all:
How does a computer understand meaning?
Transformer suggests one answer:
perhaps understanding is what happens when information is represented in the right space and the right relationships are built inside that space.
That does not mean LLMs understand in the human sense. They do not have consciousness, intention, or lived subjectivity. Their intelligence is closer to a highly sophisticated system of statistical pattern formation and contextual reconstruction.
But it also raises an uncomfortable philosophical possibility:
are we fully sure that what we call human understanding is not, at least in part, also built from highly structured patterns of relation?
References
https://www.youtube.com/watch?v=eMlx5fFNoYc https://www.youtube.com/watch?v=GGLr-TtKguA&t=2552s