做一个贝叶斯主义者

引言
今天读完了《刘嘉概率论通识讲义》,我必须承认,我非常震撼。回想我上一次那么认真去学习概率论还要追溯到高二的时候,那时在课上学习排列组合、条件概率、贝叶斯法……但是我印象最深刻的却只有不断的刷题,而概率论对我的人生有什么帮助我则毫无认知。
今天读完了《刘嘉概率论通识讲义》回想上一次认真学习概率论,已经是高二的时候了。当时课堂上学的是排列组合、条件概率、贝叶斯法等内容,但记忆最深刻的却只有无尽的刷题。至于概率论对人生的启发,我几乎毫无概念。直到大学后,我才逐渐意识到通识课程,尤其是哲学和数学,对我们一生的意义与帮助。然而,由于专业的限制,我始终没有机会系统化地学习这些知识。即便如此,这并未阻碍我通过各种媒介,在不同场合汲取这些无价的养分。
前两个礼拜,我看完《纳瓦尔宝典》,我不夸张的说,这本书是现代年轻人想要上一层楼的第一个基石性的阶梯。而其中有一句话让我印象深刻:
数学是大自然的语言。所以,我们可以利用数学对大自然进行逆向工程,以此了解大自然。不过,我们目前的了解也只是皮毛。但幸好,作为普通人我们并不需要掌握很多数学知识,只需要知道基本的统计学、算术等就够了。你应该对统计学和概率了如指掌,烂熟于心
除了这一段话之外,纳瓦尔在本书中不下三次强调概率与统计对于普通人获得成功的重要性。可见,不论我的科系是什么,只要我想要在未来有一番作为,最基本的数学常识与生活中的应用是我不能绕开的界碑。因此,我希望这本书能带我重新回顾我高中学习过的种种概率论知识点,但最重要的是我希望能从中面对现实中困难复杂问题时抽丝剥茧直击本质,做出明智决策的思维方式

概率论是什么?
用作者话来讲,概率论解决随机问题的本质就是把局部的随机性转变为整体上的确定性。且,概率论不是帮你预测下一秒会发生什么,而是为你刻画世界的整体确定性。而我认为概率论是与不确定性共存的科学与艺术。我们的世界一直处在一个极大的不确定性中,正所谓这个世界唯一不变的事物就是变化本身,明天和无常我们无法知道先到来。
然而,当用心去对世界的观察并记录后,我们会发现好像在这持续变化的世界中一些事情是有发生发生规律的,换言之是有一定确定性的。而我们依靠着这确定性,就仿佛我们在洞穴生出火种一般,虽然光线微熹,但却能照亮黑暗的一隅。因此,学习概率论的思维方式,并不能帮我准确的预料到未来会发生的事情。但是我能通过概率的分析,降低我在面对巨大不确定性时的不适感与排斥。
概率是对随机事件发生可能性大小的定量描述。随机事件是样本空间中的一种选择,每个随机事件的元素都属于样本空间。而我们对世界的探索,就是对样本空间的完善。比如说:原子衰变到底能放出多少种粒子?决定恒星运动的力到底有多少种?影响股票涨跌的因素到底有多少种?……人类探索未知世界的每一次突破性进展,其实都是在完善我们的样本空间。而在我看来,是对“读万卷书,行万里路”的最佳注解,因为我们会在这个过程中逐步完善我们作为个体所观测到的样本空间,让我们对世界的认知更加全面和清晰。这让我想起来之前在42章经的一集博客里至今让我印象深刻的一句话:
今天很多人没见识,因为只见过高端,没见过极端。但是这个世界是由极端构成的,这个世界不是由高端构成的。所以很多人高高在上,突然一夜之间创业发现落不了地,很多创业者他的这个眼睛会很狭窄,只会看到特定方向、特定领域的很窄的那些东西。他认为这就是世界。
我们一直强调要长见识长见识,但是长见识不是仅意味着出国,去最好的大学参观,去看世界最美的景色。而是去感受世界的极端,我住过最豪华的酒店,也住过挂壁房;看过最壮丽的山川,也在贫民窟的垃圾山里穿行,两个极端之间将会让我们意识到世界的张力。回到概率论,这将会让我们的样本空间逐步完备。
概率的底层逻辑
大数定律
随着试验数据的不断累积,频率和概率的差距会越来越小。也就是说,只要试验重复的次数或者观测的数据足够多,随机事件发生的频率就会无限接近它的概率。这就是我们现在常说的“大数定律”。
均值回归
均值回归的意思是,如果一个数据和它的正常状态相比有很大的偏差,那么它向正常状态回归的概率就会变大。
数学期望
数学期望是对长期价值的数字化衡量
方差
方差描述的是随机结果围绕数学期望的波动范围
标准差
标准差是方差的平方根,真正有明确的现实意义的、衡量波动性的数值 大数定律把局部的随机性变成了整体上的确定性,也就是概率;而数学期望又把概率代表的长期价值变成了一个具体的数字,从而方便我们进行比较。这两个概念是有递进关系的,正如前文所言,概率论是与不确定性共存的科学与艺术。****“共存”并非指的是对不确定性毫无作为,而是我们该如何去寻找不确定性中的确定性。大数定律是概率论中的黄金法则。当我们观察一个单独的随机事件时,结果是不确定的。例如,抛一枚硬币一次,你无法准确预测会是“正”还是“反”。但如果我们重复抛硬币很多次,比如一万次,虽然每次结果依旧是随机的,但正反面出现的比例会逐渐接近50%。这种现象就是大数定律的体现。当试验次数足够多时,结果的平均值会越来越接近理论上的概率。
这种规律性的“确定性”隐藏在大量的随机事件之中。在我看来,这种确定性在一个更长期的尺度来看就是一种期望。而这就是引入数学期望的概念,它将随机变量的可能结果与对应的概率结合起来,得出一个“平均值”或“长期结果”。它将随机变量的可能结果与对应的概率结合起来,得出一个“平均值”或“长期结果”。这个具体要怎么理解呢?
概率是抽象的,得到每个点数的概率都是$\frac\{1\}\{6\}$ 。但数学期望会将这种抽象概率转化为一个具体数字:
掷骰子的数学期望 = $1 \times \frac\{1\}\{6\} + 2 \times \frac\{1\}\{6\} + \dots + 6 \times \frac\{1\}\{6\} = 3.5$
**这样的加权计算之后,可见投骰子的长期平均值是3.5。这意味着,我们投一万次的骰子,这个平均数会接近于3.5。**因此当我们面临选择时,数学期望将不同随机事件的长期价值量化为具体数字,从而让我们方便地进行比较。
但同时,我们也要特别注意数学期望相同,并不代表两件事的价值就一样。随机结果的波动程度,同样对一件事的价值、对我们的决策有着巨大的影响。在描述和思考一个随机事件时,我们还得考虑这种波动性。这就涉及一个专业概念——方差。 正如前文所言,方差反映的是随机结果围绕数学期望的波动范围方差衡量的是波动性,方差越大,波动性则越大。因此,方差本身就是对风险的度量。但是方差本身并没有什么现实的含义,但是另一个概念——标准差(方差的平方根),才是一般而言用以衡量波动性的数值。
以下让我们用一个具体的案例来看看这些概率的基本概念是怎么运用在实际生活的:
案例:股票与债券的期望收益与方差分析
假设你有10万元,考虑两个投资选择:
- 股票市场(高风险高收益):
- 市场好(概率 0.4),收益率 $
r_1 = 20\%$ - 市场一般(概率 0.3),收益率 $
r_2 = 5\%$ - 市场差(概率 0.3),收益率 $
r_3 = -10\%$
- 市场好(概率 0.4),收益率 $
- 债券市场(低风险低收益):
- 固定收益率 $
r = 3\%$
- 固定收益率 $
- 计算股票的方差与标准差 步骤一:求股票的数学期望 $$
E(r_{\text{股票}}) = 0.4 \times 20% + 0.3 \times 5% + 0.3 \times (-10%) = 6.5% $$
步骤二:求股票收益率的方差 方差公式: $$
\text{Var}(r) = \sum_{i=1}^n p_i \cdot (r_i - E(r))^2 $$ $$ 其中 p_i 是概率, r_i 是对应的收益率, E(r) 是期望值 $$ $$
\text{Var}(r_{\text{股票}}) = 0.4 \times (20% - 6.5%)^2 + 0.3 \times (5% - 6.5%)^2 + 0.3 \times (-10% - 6.5%)^2 $$
最后可得方差: $$
\text{Var}(r_{\text{股票}}) = 0.00729 + 0.0000675 + 0.0081675 = 0.015525 $$
标准差(波动性)是方差的平方根: $$
\sigma_{\text{股票}} = \sqrt{0.015525} \approx 12.46% $$ 债券的方差 债券收益固定(3%),没有波动: $$
\text{Var}(r_{\text{债券}}) = 0, \quad \sigma_{\text{债券}} = 0 $$
- 结果
投资选项 期望收益率 标准差 风险描述
股票 6.5% 12.46% 高风险,高收益
债券 3% 0 低风险,低收益
- 结论 通过结合以上几个重要的概率底层思维,我们获得了对于未来市场不确定性的精准刻画,也给我们的投资决策提供了指引。对于风险厌恶者,由于债券收益稳定,风险为零,债券是最佳选择。对于风险中立者,根据期望收益,股票更优,但需要承担 12.46% 的波动性。但同时,我们也能透过多元化资产配置优化风险和收益。在实际应用中,现代金融学中的均值-方差模型和有效前沿理论正是基于期望收益与风险方差,帮助投资者找到最优的资产配置方案。
案例:生活中的实力与运气
我们的生活中运气和实力总是互相作用,但是当我们开始回顾一件事情为什么成功,我们往往无法定量的去分析究竟二者哪一个起了更大的作用。书中作者提了一个绝大多数人都会经历的案例——准备考试:
假设一个期末考试中,你需要掌握100道题,而你已经掌握了其中的80道题,这就是你的实力,意味着你对这些题的掌握率是80%。但是,明天的期末考试会从这100道题中随机抽取20道题来考。那么你明天能考多少分呢?答案是:不知道。
为什么呢?因为考试成绩不仅取决于你的实力,还取决于运气。运气体现在:考试随机抽取的20道题里,有多少是你会做的。
- 如果运气很好,抽到的20道题全是你会的,那么你可以考100分。
- 如果运气很差,抽到的20道题全是你不会的,那么你只能考0分。
- 大多数情况下,抽到的20道题里,会做的题大约是80%的比例(也就是16道题),那么你大概能考80分。
但是,这只是一个概率上的平均值。一次考试的结果可能会偏离这个平均值,比如运气好一点多考几分,运气差一点少考几分。 所以: 实力决定了你的平均得分(数学期望),比如80分。 运气决定了你某一次考试的具体得分(波动范围)。
如果你考很多次,每次都随机抽20道题,那么你的平均成绩会接近80分,这就是你的真实实力。但单次考试的成绩可能会因为运气好坏而有所不同。实力是稳定的,而运气是不确定的。 $$ 运气=结果-实力 $$ 孙子兵法中也是这么说的:
孙子曰:昔之善战者,先为不可胜,以待敌之可胜。不可胜在己,可胜在敌。故善战者,能为不可胜,不能使敌之可胜。故曰:胜可知,而不可为。 成功必有大量的、充分的、长期的积累,便能活在他人的想象之外。而这就是积累纯实力,从概率的角度而言,这能提高整体数学期望,降低波动性(运气)在成事中的作用。
概率分布模型
每一个随机事件都有自己的概率分布。随机事件不同,其概率分布自然也不同。但经过不断的研究,数学家们逐渐发现,不同事件的概率分布也是有规律可循的。正是这种规律,使得数学家可以通过抽象的模型,对看似随机、无序的世界进行描述和预测。一般情况下,面对一个需要去研究的现象,专家会先假设它服从某个概率分布模型,然后再去验证这个假设。
正态分布(高斯分布;Normal Distribution)
正态分布就广泛存在于自然科学、社会科学和工程学等各个领域。从人的身高、考试分数到测量误差,正态分布几乎成为了“随机现象的基石”。其钟形曲线揭示了大多数数据围绕均值分布,越偏离均值的概率越低。
正态分布中还有三个重要的数学性质
-
性质一:均值就是数学期望
-
性质二:极端值很少
-
性质三:标准差决定“胖瘦
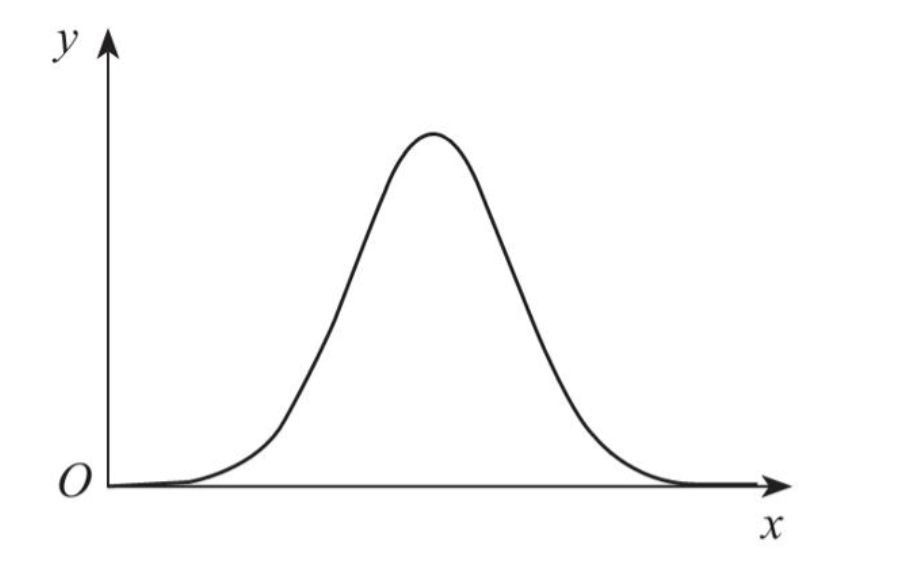 正态分布为什么会那么重要呢?甚至作者还将正态分布称为是概率分布中的神。
说一个事物是神,那它至少得有三个特性:**第一,合法性,有东西证明它合法;第二,正统性,作为参照系,能对所有事物施加影响;第三,主宰性,代表这个世界的底色和归宿。**而这三个特性,正态分布全部具备。
正态分布为什么会那么重要呢?甚至作者还将正态分布称为是概率分布中的神。
说一个事物是神,那它至少得有三个特性:**第一,合法性,有东西证明它合法;第二,正统性,作为参照系,能对所有事物施加影响;第三,主宰性,代表这个世界的底色和归宿。**而这三个特性,正态分布全部具备。
1.合法性:中心极限定理提供保证
中心极限定理 大量独立的随机变量相加,无论各个随机变量的分布是怎样的,它们相加的结果必定会趋向于正态分布。 换言之,无论随机变量的原始分布如何,当独立随机变量的数量足够大时,它们的和或均值会趋近于正态分布。这一结论让我们能够在复杂的现实世界中,通过正态分布的简化假设,对大量数据进行有效建模和预测。例如,在股票市场中,尽管单日涨跌波动很大,但长期观察下收益率的分布往往近似正态。这就揭示了为什么正态分布普遍存在的原因,”中心极限定理是因,正态分布是果。因为中心极限定理存在,所以正态分布才必然正确。”而结合上一章所提到的大数定律,当试验次数趋于无穷时,随机事件的平均值会接近于理论期望值。我们就有了概率论的两大“黄金定理”。而有了中心极限定理作为正态分布的合法性,让我们继续看看为什么正态分布如何满足其他两个要件:
2. 正统性:正态分布是所有分布的参照系
在统计学中,当我们不知道某个随机事件服从什么概率分布模型时,最常见的方法就是假设它服从正态分布,然后再用数据验证。正态分布就像一个参照系服从正态分布的随机事件,可以直接用正态分布分析;不服从正态分布的随机事件,也要利用正态分布与之比较。
3. 主宰性:正态分布是世界的宿命
-
正态分布普遍存在。 中心极限定理告诉我们,只要随机事件受很多独立因素共同作用,无论每个因素本身是什么分布,这个随机事件最终都会形成正态分布。所以说,正态分布具有普遍意义。
-
所有概率分布最终都会变成正态分布。 无论是对数分布、幂律分布,还是指数分布,又或者是其他任何分布,只要自身不断演化,不断叠加自己,最终都会变成正态分布。或许我们可以这么说:所有的概率分布,不是正态分布,就是在变成正态分布的路上。
-
第三,正态分布是世界的宿命。 在证明中心极限定理之后,信息论领域发现了“熵最大原理”。信息论中的熵是对信息不确定性的度量,熵最大原理则是指,一个孤立系统总是朝着不确定性最大的方向发展。也就是说,在一个孤立系统中,熵总是在不断增大。而巧合的是,在均值和方差确定的条件下,信息熵最大的分布方式就是正态分布。如果熵不断增长是孤立系统确定的演化方向,那熵的最大化,即正态分布,就是孤立系统演化的必然结果。因此,正态分布就像是上帝创造出来的一样。存在即合理,一切冥冥之中早已被注定着。
其他的概率分布模型
数学家进一步发现,不同的概率分布具有各自的特点与适用场景:
-
指数分布(Exponential Distribution) 描述事件发生的时间间隔,如电话呼叫间隔、设备故障时间,强调短时间内发生的概率更高,随着时间增加概率逐渐减小。
-
泊松分布(Poisson Distribution) 描述单位时间或空间内事件发生的次数,如商场顾客到来频率、网页点击次数,适合稀疏随机事件的计数问题,强调平均发生率的稳定性。
-
幂律分布(Power-Law Distribution) 描述少数极端值占主导的现象,或描述世界中的不平衡分布现象,如城市人口分布、大规模网络中的节点连接数,富豪与普通人的财富差距。强调“少数占多数”的特点,广泛应用于自然现象和社会复杂系统。
⚠️幂律分布 和 大模型的 Scaling Law 幂律法则 虽然都涉及幂律(Power Law)关系,但它们的背景、应用场景和侧重点不同:
- 大模型(如 GPT)中的 Scaling Law 描述了模型性能随着规模增长(数据、参数、算力)呈现的幂律关系。
- 实践发现:当参数量、训练数据量和算力不断增加时,模型的性能(如损失函数、准确率)会按照幂律规律提升,但提升速率逐渐减小。
- 数学关系【 N :模型的规模(参数量、数据量或算力)】 $$
\text{Loss} \propto N^{-\beta}
$$
概率vs统计
概率和统计其实是两个不同的学科,虽然我们经常把二者放在一起讨论,在国内大学里,课程的名字也是:《概率论与数理统计》,但其实二者的研究问题刚好相反。
概率研究问题的思路是,对世界已经有了一个全景式的了解,来判断未来会发生什么。用数学的语言来说,就是已知一个模型和参数,怎么去预测这个模型产生的结果的特性(例如均值、方差、协方差等)。
统计研究问题的思路则相反。统计从上帝视角转为人间视角:我只有眼前的一堆数据,要利用这堆数据去预测世界可能的全景究竟是什么。
一句话总结:概率是已知模型和参数,推数据;统计是已知数据,推模型和参数。简单地说就是,概率用上帝视角预测这个世界的未来,统计用现实的视角揣测世界的本来面貌。
贝叶斯
再进入到最重要的贝叶斯之前,我们必须先了解一个概念:条件概率
条件概率
所谓的条件概率,简单来讲就是,如果一个随机事件发生的概率会因为某个条件而发生变化,那在这个条件发生的情况下,这个随机事件发生的概率就是条件概率 条件概率是指在一个事件 B 已经发生的前提下,另一个事件 A 发生的概率,记作 P(A | B) 。 $$
P(A | B) = \frac{P(A \cap B)}{P(B)}, \quad P(B) > 0 $$
严格意义上来看,很多我们以为完全独立和随机的时间,其实有时有条件的,因此所有的概率都是基于条件的,而现实世界中所有的概率都是条件概率。
贝叶斯推理
根据新信息不断调整对一个随机事件发生概率的判断,这就是贝叶斯推理。 概率是对信心的度量。更为细致一些,概率是对不确定是否会发生的事件推测其是否会确定发生的信息。是我们对某个结果相信程度的一种定量化表达。
贝叶斯定理(Bayes’ Theorem)
贝叶斯定理描述了如何根据新的信息(证据)更新我们对某个事件的概率的判断。它将先验概率与新信息结合,得出后验概率。 公式: $$
P(A | B) = \frac{P(B | A) \cdot P(A)}{P(B)}, \quad P(B) > 0 $$
有人话翻译这个公式就是
现象B出现的情况下事件A发生的概率,等于事件A发生时现象B出现的概率,乘以事件A发生的概率,再除以现象B出现的概率。
有比较严谨的语言来表达就是: P(A | B)表示在现象B出现的条件下,事件A发生的概率(后验概率); P(B | A)表示事件A发生时,现象B出现的概率(似然); P(A)表示事件A发生的先验概率,即原本对A发生的判断(先验概率); P(B)为现象B出现的概率。(信息的概率)
那要如何理解这些概念呢?
- 先验概率(Prior Probability)
- 这是我们最初的判断,即在没有新信息之前,对事件发生的可能性估计。
- 例:假设你知道有1%的人患有某种病,那么在没有其他信息时,某人患病的概率就是1%
- 似然(Likelihood)
- 似然或称为新证据是指在给定某个假设的前提下,观察到某个结果的概率。它反映了假设对数据的解释能力。如果有新的信息(比如一个医学测试结果),我们需要考虑在这种情况下事件发生的可能性。
- 后验概率(Posterior Probability)
- 将先验概率与新证据结合起来,得出更新后的概率。
做一个贝叶斯主义者
贝叶斯理论的使用已经渗透到我们生活中的各个方面,如医学诊断,搜索引擎推荐,机器学习算法等。但是我认为贝叶斯对于我们而言,更是一种无价的思维方式。先用最简单的方式总结一下贝叶斯:根据新信息调整对概率的判断。但是,大道至简,从一句总结中我们能派生出两点很重要的人生智慧。
- 起点不重要,迭代很重要
- 信息越充分,结果越可靠
1. 起点不重要,迭代很重要
贝叶斯不是推理一次就结束了,它是一个不断迭代的过程。每找到一个新信息,就会进行一次推理,得到一个新判断。而下一个信息,要么进一步证实我们的判断,要么削弱我们的判断,从而让我们对之前的判断进行调整。这样不断微调,慢慢地,结果一定会和真实状况越来越接近。贝叶斯的特征与我自己的一个人生信条有着非常强烈的呼应:
先完成,再完美。
我会发现不仅仅是我,我身边的许多同学都有“完美主义”洁癖,总是要想着一件事情想的够清楚了,做好足够的准备了,才选择去做。但是这在我看来是不对的。因为,一件事情要成的很多要素信息仅仅只有在实操的过程中才能获取,然而缺乏这些实操的信息的回馈,我们将无法调整自己对概率的判断。因此,不要太过担心自己的起点,重要的是时刻要警觉在过程中的重要信息(证据),这也是为什么复盘是所有大佬都会有的共同习惯。之前跟着清华一个很有名的科技公司CTO吃饭,他就提到了美团的王兴就是一个“复盘狂魔”。在他创业初期,就经常跟她的爱人在华清嘉园的小区里散步复盘。复盘迭代的周期以“日”计算。由此可见,作为一个连续创业者,除了敢想更敢做的超强执行力外,王兴的复盘习惯也让他一步步打造出了属于自己的美团帝国。瑞达利欧也在《原则》一书中讲到过:
If you look back on yourself and don’t think you were dumb then, you mustn’t have learned much.

2. 信息越充分,结果越可靠
尽可能丰富充分的信息,是贝叶斯走向准确的最大保障。 这让我联想起大语言模型,其核心在于一个字“大”。这个大指的维度有很多,但其中一个就是数据量的大。大语言模型的训练需要海量的数据,涵盖不同语言、主题、风格、格式,甚至包括代码、对话、书籍、新闻等各种文本。这些数据支撑模型的学习,使其具备丰富的语义理解和生成能力。而我们在进行决策的时候何尝不是如此。若能将越充分且角度越多维的信息吸收到我们脑海中,我们才更有可能用一个颗粒度更细的尺度刻画出一个不确定性的事情。因此,无时无刻我们都要保持着开放的态度与心态,千万不能因为自己的偏见和无知去屏蔽某一特定方面的信息。举个例子,比如我今天做了一个演讲,台下的人都在说夸赞我演讲能力非常好。此时,我们更应该去将注意力放在其他不同类型的评价上,比如说批评、 不满等。唯有这般,我才能构建对自己此次演讲一个更立体的反馈,更有效的去进行复盘。 充分并不等于“多”,充分在这个语境下指的是各种面向的信息都有所吸收。因此,我觉得不论何时何地,无论我们的成就是高是低,都应该像乔布斯说的:
Stay Humble Stay Foolish

结尾
这本书并不长,但是我很欣赏作者把复杂概念简化后的输出能力。可能它并不适用于未来有志于从事相关研究的同学,但是于我而言,我更多希望从这本书中获得的是站在概率的高地思考分析这个世界,迭代认知系统。具体而言,提高自己的概率思维是我读这本书的核心目的。在未来,如果我忘记了这本书以上的种种内容,我希望以下是我能带走的:
提高概率思维的三大原则
原则一:对抗直觉,能算就算
人脑习惯性的凭直觉会做出自然且正确的选择。但是随着社会变得越来越复杂,我们依赖直觉所做的决策准确性越来越差。且现代很多的套路正是仰仗于我们过度依赖直觉导致我们判断错误。这时候,我么要做的就是极力遏制使用直觉的冲动,去寻找更多的信息、数据去计算概率。正如孙子兵法所说的:
计,算也。曰:计算何事?曰:下之五事,所谓道、天、地、将、法也。于庙堂之上,先以彼我之五事计算优劣,然后定胜负。胜负既定,然后兴师动众。用兵之道,莫先此五事,故为篇首耳。
原则二:寻找条件,增大概率
当我们在计算的时候,也不是漫无目的的去尝试算出一个精准的数值。我认为最重要的目的是,去抽丝剥茧出那个对成功影响最大的条件,并且尝试控制这个条件,让成功的概率最大化。举个例子,比如说今天想要成为一个好的销售有非常多的环节和要点需要去考量。但是,成为一个好销售最关键的条件无他就是简单的:赢得信任。而赢得一个人的信任最关键的就是以下三点,只要做好这三个点就能极大增加销售成功的概率:
说ta喜欢听的话,送ta喜欢的礼物,解决ta解决的问题
原则三:相信系统,长期主义
所有未来发生的事都是一个概率,而活在当下的我们经常会担心自己所做的决策是否能引领我们到达理想的彼岸,往往我们会通过短期的回馈进行判断决策的正确性。但就像前文所言,波动性的存在使得我们决策的结果存在一定的随机性。很有可能站在更长期的尺度,我们现在的决定是正确的。但是因为短期内的负反馈我们就退缩了。然而,就像是这个原则所言,我认为再找准一个大方向的前提下,根据信息不断调整方向,并相信系统,相信长期主义,相信“相信”的力量。直到未来的某一刻,你会发现“结果”将在不知不觉间已经攥在了手里……
$$ 1.01^{365} = 37.8 $$ $$ 0.99^{365} = 0.03 $$
(全文完)
2024/12/17 记于清华园