Be a Bayesian

Introduction
After finishing Liu Jia's General Probability Lecture, I realized how shallow my earlier understanding of probability had been.
The last time I had studied probability seriously was in high school. Back then I learned permutations, combinations, conditional probability, and Bayes' theorem, but what stayed with me was not the beauty of the subject. What I remembered most was endless problem sets. I had almost no sense of what probability theory might have to do with real life.
Only after entering university did I gradually realize how important mathematics and philosophy are as lifelong tools for thinking. Even though I never had the chance to study them systematically in college, that never stopped me from absorbing their value through books, lectures, and conversations.
Two weeks ago I finished The Almanack of Naval Ravikant. One line in particular stayed with me:
Math is the language of nature... As ordinary people, we do not need advanced mathematics, but we should know statistics and probability extremely well.
Naval returns to that point again and again. If I want to do anything meaningful in the future, then a practical command of mathematics, especially probability and statistics, is not optional. That is why I wanted this article to do two things for me:
- revisit the probability ideas I first learned in school
- extract a way of thinking that helps me make better decisions in a messy and uncertain world
What Probability Theory Really Is
In plain language, probability theory turns local randomness into global certainty.
It does not tell you exactly what will happen in the next second. Instead, it helps you describe the larger structure behind uncertainty.
That is why I think probability theory is the science and art of living with uncertainty.
Our world is fundamentally unstable. The only constant is change. We do not know whether tomorrow will bring opportunity, chaos, luck, or loss. But careful observation reveals that even in a changing world, patterns still exist. Probability does not eliminate uncertainty. It helps us find the part of uncertainty that can still be understood.
Probability is a quantitative description of how likely a random event is to occur. Every random event exists inside a larger sample space, and one way to understand human progress is to see it as the continual expansion and refinement of that sample space.
When physics discovers more about particles, when astronomy explains more about stars, when finance models more of the forces driving markets, we are, in effect, improving the sample space through which we interpret the world.
That is also why I think the phrase "read ten thousand books and travel ten thousand miles" has a probabilistic meaning. The broader and richer your experience, the more complete your personal sample space becomes.
I once heard a line that has never left me:
Many people have seen only the high end of the world, but not its extremes. Yet the world is built more by extremes than by luxury.
That line matters. Real understanding does not come only from elite schools, beautiful views, and polished surfaces. It also comes from tension, contrast, and seeing both abundance and hardship up close. In probabilistic language, that means letting reality enrich your sample space.
The Core Logic of Probability
Several ideas form the practical foundation of probability thinking.
Law of Large Numbers
As the number of trials grows, observed frequency gets closer and closer to true probability.
A single coin flip is unpredictable. Ten thousand flips reveal structure. This is one of probability theory's deepest promises: randomness at the micro level can produce stability at the macro level.
Regression to the Mean
When a result deviates sharply from its normal state, it is often more likely to move back toward the average later.
This is a useful antidote to overreaction. Extreme outcomes often trigger dramatic stories, but many are simply statistical swings that later normalize.
Expected Value
Expected value is the numerical expression of long-term value.
Take a fair die. The probability of each face is 1/6, but the expected value is:
1*(1/6) + 2*(1/6) + 3*(1/6) + 4*(1/6) + 5*(1/6) + 6*(1/6) = 3.5
You will never roll a 3.5 on a single throw, but across many throws the average result approaches 3.5. That is what expected value gives us: a way to compare choices in long-run terms.
Variance and Standard Deviation
Expected value alone is not enough. Two options can have the same expected value but very different risk profiles.
- Variance measures how widely outcomes spread around the expected value.
- Standard deviation is the square root of variance and is usually more interpretable in practice.
In real life, variance is one way of describing risk.
Probability, expected value, and variance form a progression:
- probability tells us what may happen
- expected value tells us the long-run average payoff
- variance tells us how painful or volatile the ride may be
A Concrete Example: Stocks vs. Bonds
Imagine you have RMB 100,000 and are choosing between stocks and bonds.
Option A: stocks
- 40% chance of
+20% - 30% chance of
+5% - 30% chance of
-10%
The expected return is:
0.4*20% + 0.3*5% + 0.3*(-10%) = 6.5%
That is better than the bond's return. But the outcomes swing much more, which means high variance and high risk.
Option B: bonds
- fixed return of
3%
The expected return is lower, but the variance is essentially zero.
That simple comparison already teaches an important lesson:
- risk-averse people may rationally prefer the lower-return bond
- risk-neutral people may prefer the stock
- sophisticated investors may combine both
Modern portfolio theory is built on exactly this logic: expected return matters, but so does variance.
A Second Example: Skill and Luck
One of the best examples in the book is exam preparation.
Suppose there are 100 possible final exam questions, and you truly know 80 of them. That means your skill level is 80%.
Tomorrow, the exam randomly selects 20 questions.
How much will you score?
You do not know.
Why? Because your result depends on both skill and luck.
- If luck is excellent, the exam picks 20 questions you all know, and you score 100.
- If luck is terrible, it picks mostly what you do not know, and you do much worse.
- In expectation, your score should center around 80.
That leads to a simple but powerful model:
- skill determines expected value
- luck determines short-term fluctuation
Over many repeated trials, your average score approaches your real ability. A single result, however, can be distorted by luck.
This is why long-term accumulation matters so much. Building more real ability raises expected value and reduces the influence of luck on outcomes.
As The Art of War puts it, the best generals first make themselves unbeatable, then wait for the enemy's vulnerability.
Probability Distributions
Every random process has some probability distribution. Different processes produce different shapes, but mathematicians discovered that many seemingly random phenomena still follow recognizable patterns.
Normal Distribution
The normal distribution, or Gaussian distribution, is one of the most important probability models in science.
It appears in:
- human height
- exam scores
- measurement error
- many natural and social processes
Its bell curve captures a simple intuition: most observations cluster around the mean, and extreme values are rare.
Three practical properties matter most:
- the mean is the center
- extremes are uncommon
- standard deviation controls how wide or narrow the curve is
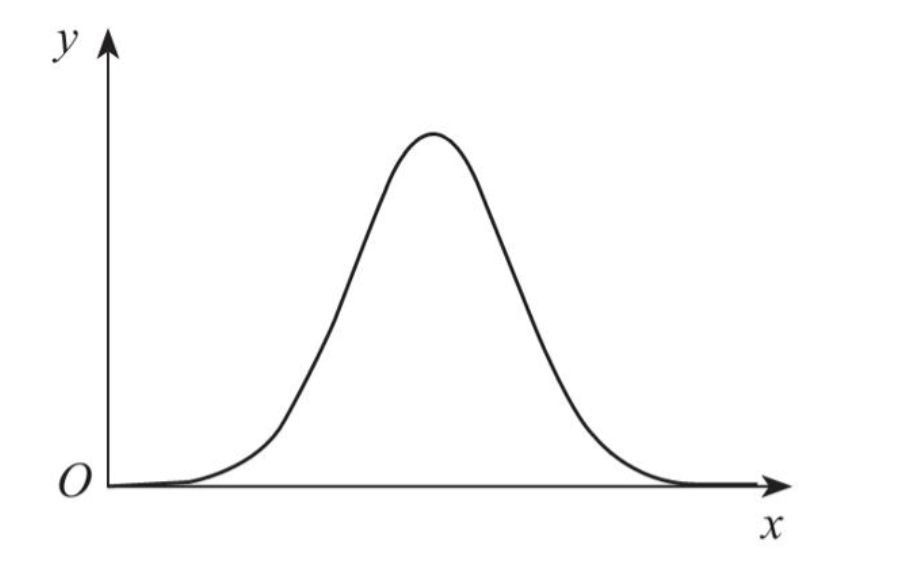
Why is the normal distribution so important?
1. Legitimacy: the Central Limit Theorem
The Central Limit Theorem tells us that when many independent random variables are added together, their sum tends toward a normal distribution regardless of the original distributions.
That is why the normal distribution appears everywhere. It is not just convenient. It is deeply justified.
2. Orthodoxy: a reference model
In statistics, when we do not yet know the true distribution of a phenomenon, normality is often the first working hypothesis. Even if a dataset is not exactly normal, the normal distribution remains a key comparison point.
3. Dominance: the pull of maximum entropy
Information theory later showed that among all distributions with a fixed mean and variance, the normal distribution has the highest entropy. In a sense, it is the most "uninformative" or most natural distribution under those constraints.
That is why it feels almost fated.
Other Important Distributions
Mathematicians later identified other highly useful patterns.
-
Exponential distribution
Models time intervals, such as waiting time between events or machine failure times. -
Poisson distribution
Models counts of events per unit time or space, such as arrivals at a shop or clicks on a page. -
Power-law distribution
Models highly imbalanced systems, where a small number of extreme values dominate, such as city size, network degree, or wealth distribution.
Power laws also appear in AI, especially in scaling laws:
- as parameters, data, and compute increase
- model performance often improves according to a power-law relationship
- but the marginal improvement gradually declines
Probability vs. Statistics
Probability and statistics are often taught together, but they solve opposite problems.
Probability
Probability starts from a known model and known parameters, then asks:
what kind of data or outcomes should we expect?
Statistics
Statistics starts from observed data and asks:
what model or parameters most likely generated this data?
One-sentence summary:
Probability goes from model to data; statistics goes from data to model.
Probability is closer to a God's-eye view. Statistics is closer to the human point of view.
Bayes
Before Bayes' theorem, we need one more concept: conditional probability.
Conditional Probability
Conditional probability asks:
if one condition has already occurred, how does that change the probability of another event?
Formally:
P(A | B) = P(A and B) / P(B), provided that P(B) > 0
Strictly speaking, much of what we call probability in real life is conditional probability, because real events almost always occur under conditions rather than in a vacuum.
Bayesian Inference
Bayesian inference means updating our judgment about an event as new evidence arrives.
Probability, in this sense, is a measure of confidence. It is a disciplined way of quantifying belief under uncertainty.
Bayes' Theorem
Bayes' theorem tells us how to combine prior belief with new evidence:
P(A | B) = P(B | A) * P(A) / P(B)
In words:
The probability that
Ais true given thatBis observed equals the probability of observingBifAwere true, multiplied by the prior probability ofA, and then normalized by the probability of observingB.
The three key pieces are:
-
Prior
Your initial estimate before new evidence arrives. -
Likelihood
How compatible the new evidence is with a given hypothesis. -
Posterior
Your updated belief after incorporating the new evidence.
Be a Bayesian in Life
Bayesian thinking already drives medicine, search engines, recommendation systems, and machine learning. But to me, its greatest value is not technical. It is philosophical.
The simplest summary of Bayes is:
update your probability judgment when new information arrives.
That one sentence contains two important life principles.
1. The starting point matters less than iteration
Bayesian reasoning is not a one-shot process. It is iterative.
Each new piece of information either strengthens or weakens our earlier judgment. Over time, repeated updating gets us closer to reality.
This fits one of my own life principles almost perfectly:
First finish it, then perfect it.
A lot of people, including many of my friends, suffer from a kind of perfectionism. They want to think everything through completely before acting. But many of the most important pieces of information can only be obtained through real execution.
Without those signals from reality, you cannot update.
That is why reflection and review matter so much. Wang Xing, the founder of Meituan, is famous for his obsession with review and iteration. Ray Dalio says something similar in Principles:
If you look back on yourself and don't think you were dumb then, you mustn't have learned much.

2. The richer the information, the more reliable the result
Bayesian accuracy depends on evidence.
This reminds me strongly of large language models. One reason they are powerful is scale: huge datasets across language, format, topic, and style. That diversity gives the model a richer internal map of the world.
Decision-making works similarly. The more complete and multi-angled the information we absorb, the better our judgment under uncertainty becomes.
But "more" is not the same as "better." What matters is not sheer volume. What matters is coverage across different dimensions.
That is why we should remain open, especially to information that challenges our ego or prior beliefs. If I give a speech and everyone praises me, the most valuable information may not be the praise. It may be the criticism, dissatisfaction, or confusion I initially want to ignore.
Only with that fuller picture can I do an honest review.
For that reason, I think we should always keep the following attitude:
Stay humble.
Stay foolish.

Closing
This book is not long, but I admire the author's ability to compress difficult ideas into clear language.
More than the formulas themselves, what I wanted from it was a better way to analyze the world from the high ground of probability and keep updating my own cognitive system.
If I eventually forget most of the details, I still hope to carry away these three principles.
Three Principles for Better Probabilistic Thinking
Principle 1: Resist intuition; calculate when you can
Human intuition can be useful, but the modern world is too complex to rely on intuition alone. Many of the traps people fall into today depend precisely on our tendency to over-trust instinct.
When the stakes matter, suppress the urge to go with the first feeling. Gather more information. Count. Estimate. Model.
Principle 2: Find the condition that matters most
The goal is not always to compute one perfect number. Often the real task is to identify the condition that most strongly drives success and then try to control it.
For example, if you want to become a great salesperson, many details matter. But the central condition is simple:
earn trust.
Once you identify the dominant condition, you can increase the probability of success much more efficiently.
Principle 3: Trust the system; think long-term
Every future outcome is probabilistic. In daily life we often judge our decisions too quickly by short-term feedback. But variance means that even a correct decision can produce a bad short-term result.
What matters is whether, on a longer horizon, the direction is right and the system is sound.
Keep updating your path with new evidence. But if the broad direction is right, then trust the compounding power of time.
1.01^365 = 37.8
0.99^365 = 0.03
That is the spirit of long-termism.
Alfred
Written at Tsinghua, December 17, 2024