一文看懂Context Engineering
上下文(Context)对于LLM产品的重要性不言而喻。这就像一位刚入职的实习生,即使是清华北大毕业的高材生,如果没有人告诉他任务的背景、目标、可用工具和方法等上下文信息,他也难以出色完成工作。同样,再强大的模型,若缺乏适当的上下文引导,也无法真正发挥其潜力,更难以满足实际产品需求。但是始终存在的制约条件是上下文是有限的,随着上下文窗口的逐渐增长,模型的性能会逐渐下降,同时也会使得成本、延迟变得更加不可控。
什么是Context Enginering
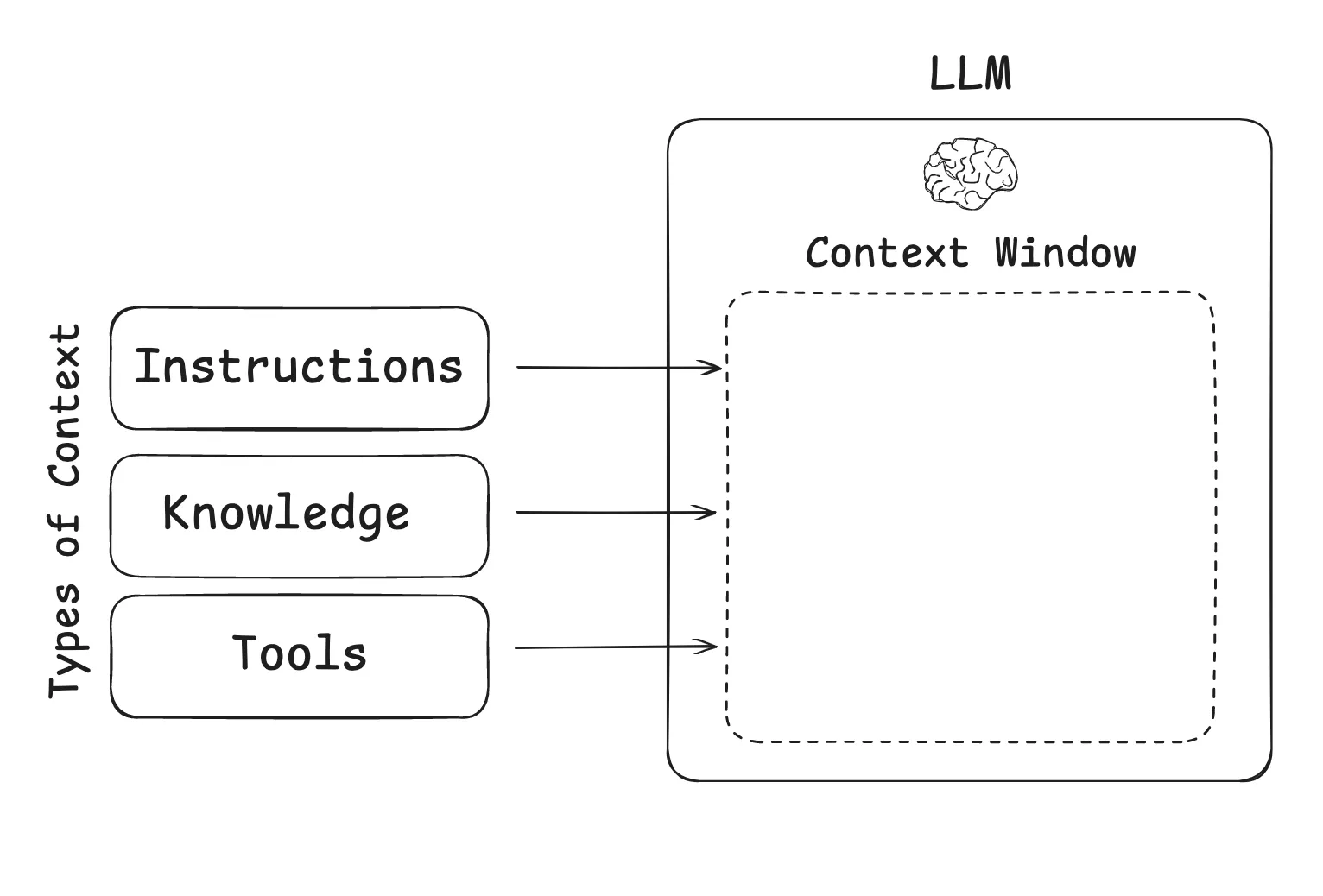
在context 中一般可以包含这三类内容:
- 指令 – 提示词、记忆、少样本示例、工具描述等
- 知识 – 事实、记忆等
- 工具 – 工具调用的反馈
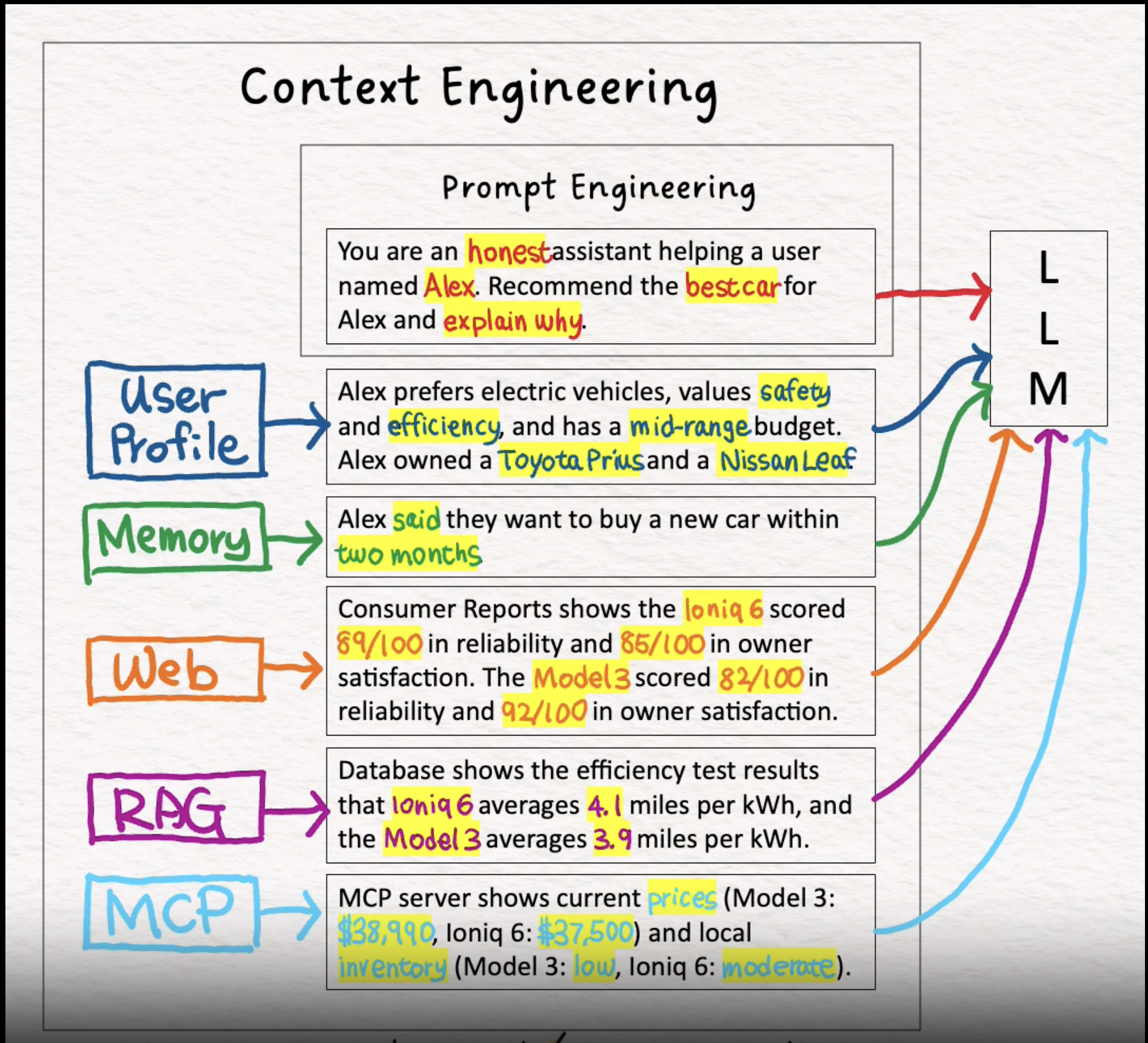
 Google DeepMind 的高级 AI 工程师 Philipp Schmid 则把上下文拆成多个组成模块,包括:
Google DeepMind 的高级 AI 工程师 Philipp Schmid 则把上下文拆成多个组成模块,包括: - **指令/系统提示: **定义模型在对话过程中行为的初始指令集,可以/应该包括示例、规则等。
- **用户提示:**来自用户的即时任务或问题。
- **状态/历史(短期记忆):**当前对话,包括导致此刻的用户和模型响应。
- **长期记忆:**持久性知识库,通过许多先前对话收集,包含学习到的用户偏好、过去项目的摘要或被告知要记住以供将来使用的事实。
- **检索信息(RAG):**外部、最新的知识,来自文档、数据库或API的相关信息,用于回答特定问题。
- **可用工具:**所有可调用的函数或内置工具的定义(例如,check_inventory, send_email)。
- **结构化输出:**关于模型响应格式的定义,例如JSON对象。
而他也对上下文工程下了个定义(目前是最清晰的):
上下文工程是设计和构建动态系统的学科,该系统能在正确的时间,以正确的格式,提供正确的信息和工具,为大语言模型(LLM)提供完成任务所需的一切。
如果用一个比喻来理解这个概念:LLM 就像是 CPU,而其上下文窗口就像 RAM,充当模型的工作内存。就像 RAM 一样,LLM 的上下文窗口在处理各种上下文来源时容量有限。而正如操作系统会安排什么内容适合加载到 CPU 的 RAM 中一样,我们可以将“上下文工程”视为发挥类似作用的过程。
为什么Agent需要Context Engineering
让我我们先看一个典型智能体的工作流程: 收到用户输入后,智能体通过一连串工具调用来完成任务。每一次迭代,模型都会根据当前上下文从预定义的动作空间中选择一个动作,然后在环境里执行该动作并产生观察结果。动作和观察结果被追加到上下文中,成为下一次迭代的输入。这个循环持续进行,直到任务完成。 可以想象,上下文在每一步都会增长,而输出——通常是一个结构化的函数调用——相对较短。这使得智能体的预填充(prefill)与解码(decoding)比例相比聊天机器人严重失衡。 智能体完成任务的过程是一个迭代循环,具体步骤如下:
- 选择动作: 在每一次迭代中,模型会分析当前的上下文信息,并从一系列预定义的可用动作中选择一个来执行。
- 执行与观察: 所选的动作在环境中被执行后,会产生一个观察结果(例如,工具调用的返回信息)。
- 更新上下文: 这个动作和对应的观察结果会被一同追加到历史上下文中。
- 循环迭代: 更新后的上下文将作为下一次迭代的输入,模型基于此再次选择新的动作。这个循环会一直持续,直到任务最终完成。
核心挑战在于,随着任务的进行,上下文会不断累积增长,而每次迭代生成的输出(通常是简短的函数调用)却相对较短。这种模式导致了Agent在计算过程中预填(Prefill)与“解码(Decoding)相比于传统的聊天机器人应用严重失衡
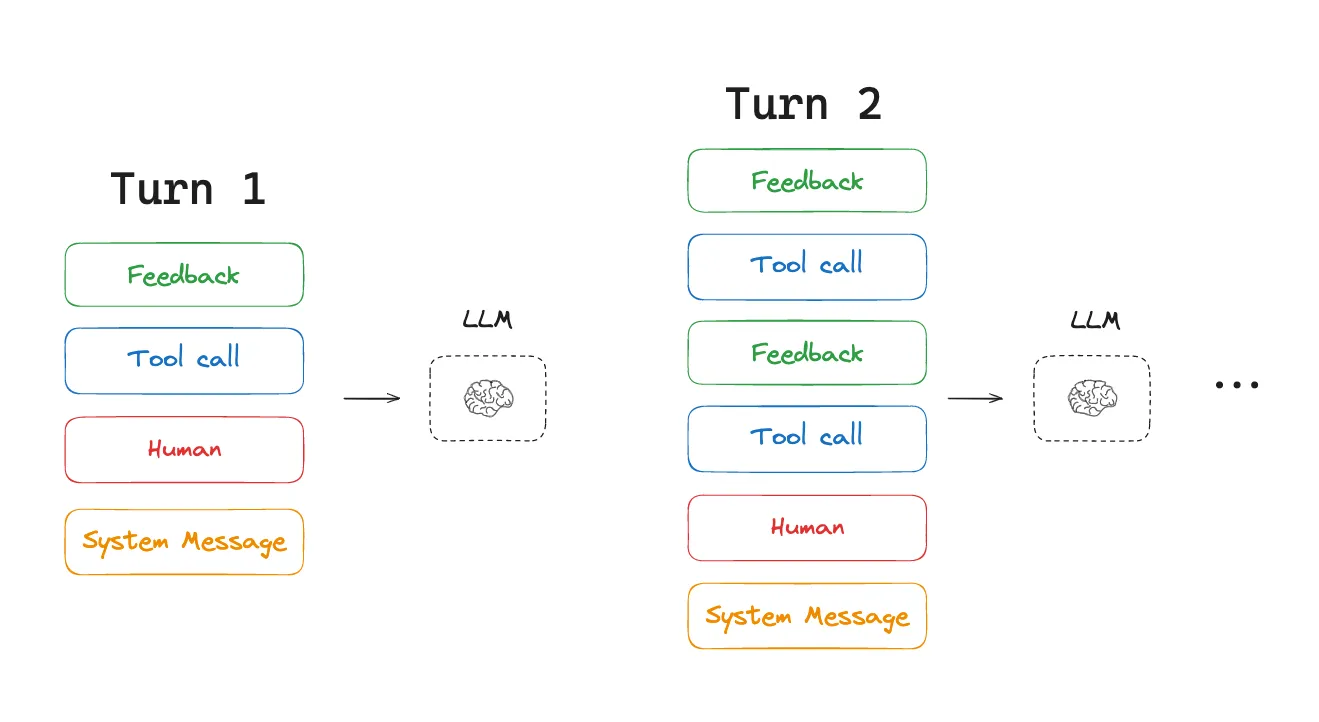 可见,随着任务难度的提升,模型将会使用大量的token,但这会引发许多的问题:超出上下文窗口的容量、导致成本和延迟激增,或者降低Agent的性能。
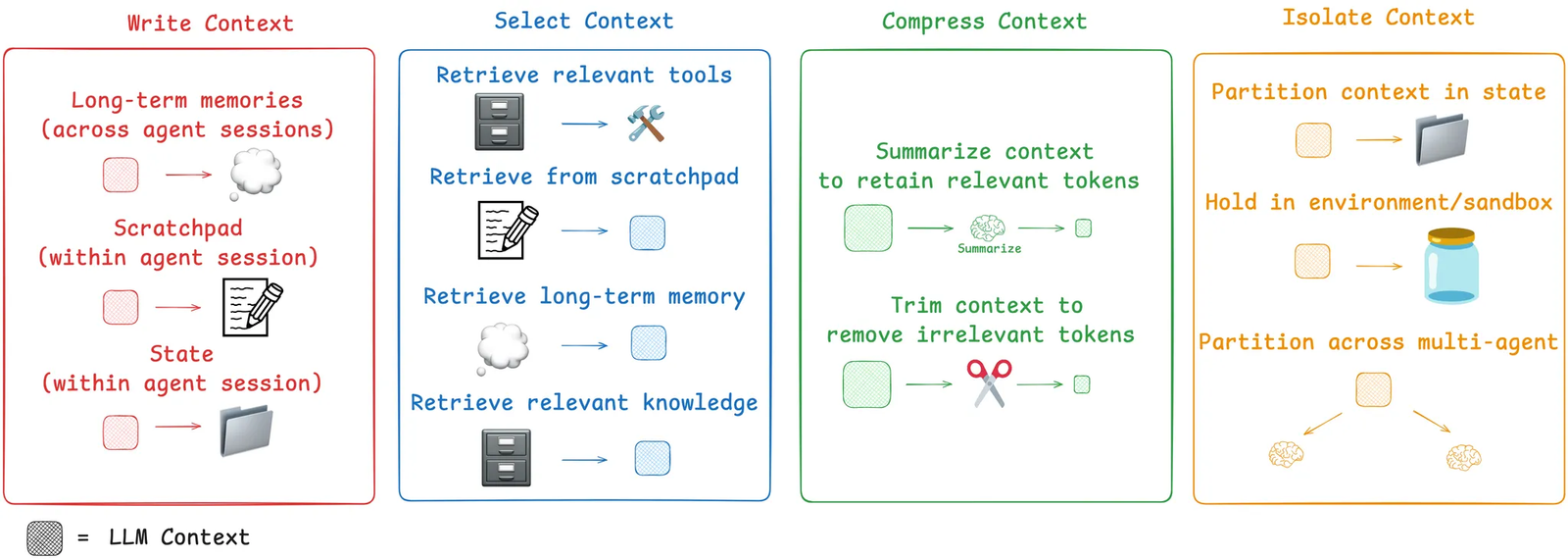
而Context Engineering 就是在尝试通过工程化方式的多种策略,其中包括以下几种: write, select, compress, and isolate。
可见,随着任务难度的提升,模型将会使用大量的token,但这会引发许多的问题:超出上下文窗口的容量、导致成本和延迟激增,或者降低Agent的性能。
而Context Engineering 就是在尝试通过工程化方式的多种策略,其中包括以下几种: write, select, compress, and isolate。
Write 写入
Writing context means saving it outside the context window to help an agent perform a task. Writing context 指的是将上下文信息保存在上下文窗口之外,以帮助智能体完成任务。
Scratchpads & Memory 草稿本与记忆
正所谓好记性不如烂笔头,就像人类做笔记一样,智能体可以把重要信息写到“scratchpad”里,这个scratchpad可以是文件、数据库、或是程序的某个持久化对象。Scrachpads是临时记忆,比如在一次对话或任务过程中,只有在当前内session当中有效,会话结束后一般就会清空了。
在实践中我们看可以看到Anthropic 在构建基于multi-agents的research system时使用了Scratchpads的方式:LeadResearcher在思考方案时,会把计划写入Memory(记忆),这样即使上下文窗口溢出(信息太多被截断),也能保留核心方案。
这样的实践我们在Manus中也可以看到,manus会在planing阶段创建一个todo.md,并且会在模型完成每一步时进行进行记录,同时也作为上下文的一部分传回模型

 相较于只能在一个session中起作用的scratchpad,memory让智能体能够跨会话、长期记住一些重要信息。如用户的偏好、历史对话、经验总结等,可以在多次任务/会话中反复使用。
相较于只能在一个session中起作用的scratchpad,memory让智能体能够跨会话、长期记住一些重要信息。如用户的偏好、历史对话、经验总结等,可以在多次任务/会话中反复使用。
Select 筛选
模型能筛选的,不仅仅只是前面提到的写入的scratchpads和memory,还包括tools,knowledge…… 模型更人一样脑子里面的事情太多就会变笨,甚至还会发生错乱,因此选的准也是context engineer的一个重要环节。
Compress 压缩
压缩上下文是解决上下文窗口有限最为直接的方法,在实践中一般会使用Trim(snip)或者是Summarize两种方法。 Summarize就是将一段长上下文通过一定策略进行总结,并最后总结作为内容留在上下文窗口中。实践中,我们可以看到Claude Code在上下文达到95%的时候,会自动执行“auto- compact”,这就是一个summarize的动作。而manus在上下文爆炸后导致session无法继续运行后,也可以选择inherit(继承)上下文到下一个新的session,这本质上也是summarize的一种实践。
至于Trim就比较好理解了,指的是对上下文(比如对话历史、文本内容等)进行删减,去掉不重要或不需要的信息,只保留有用的部分。但是这也可能会导致丢失关键信息影响模型最后的表现。
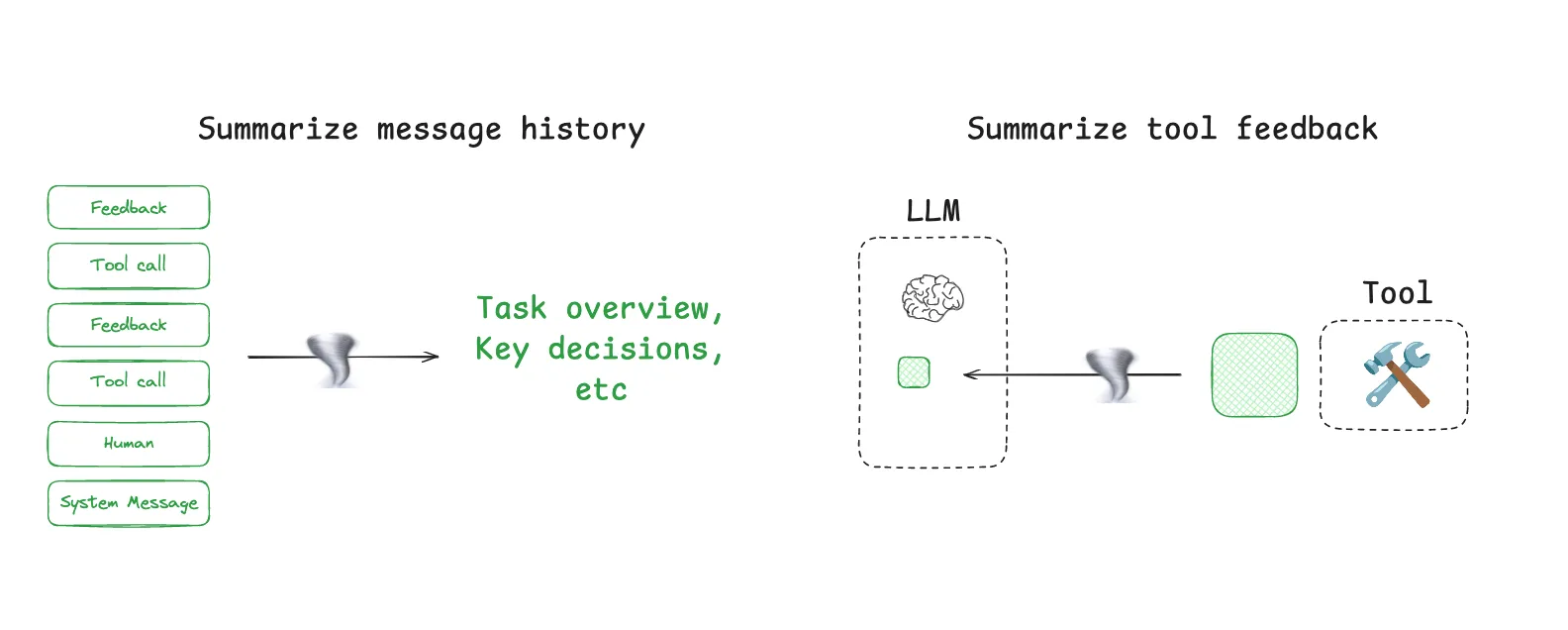
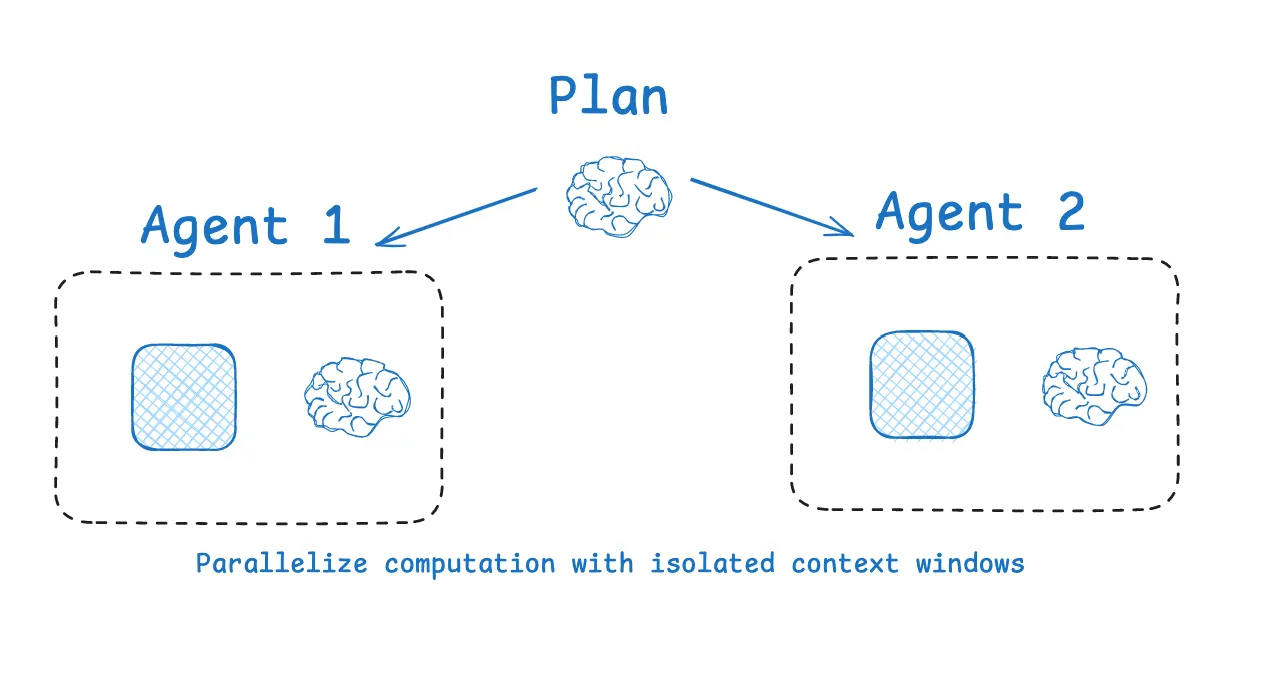
Isolate 隔离
isolate指的是将任务相关的上下文进行拆分,让智能体(agent)更好地完成任务。 **一方面,我们可以用多智能体(Multi-agent)方式,**通过让多个子智能体各自处理特定子任务,把上下文分配给不同的智能体,每个智能体有独立的工具、指令和上下文窗口。这样可以让每个子智能体专注于更窄的任务范围,提高整体效率。
Anthropic 的multi-agent researcher表明,多个隔离上下文的子智能体并行工作,效果优于单一智能体,但也带来更多token消耗、需要精细的任务分配和协调。
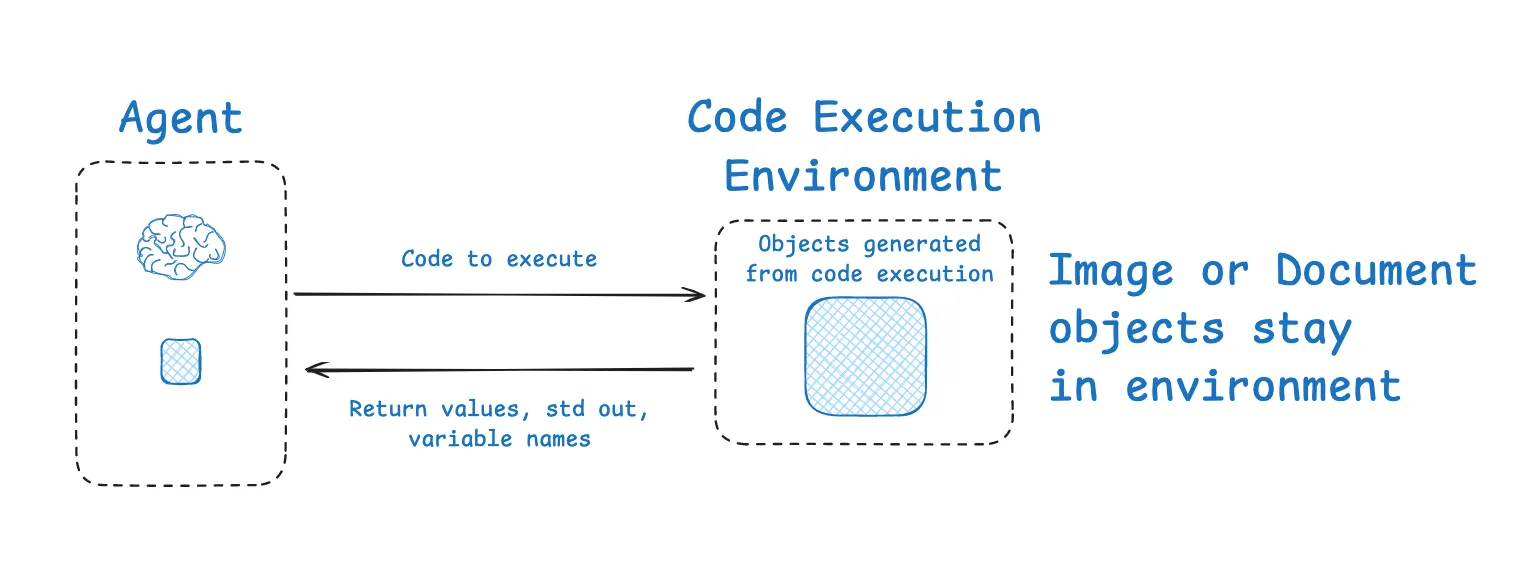
 **另一方面,我们还有环境中的上下文隔离(Environments)。**通过工具调用和沙箱(sandbox)机制,将部分上下文(如工具返回的数据、图片、音频等)隔离在外部环境,而不是直接传给LLM。这样可以有效管理和存储大体积的状态信息,让LLM只处理最相关的内容,提高上下文的有效利用率。
**另一方面,我们还有环境中的上下文隔离(Environments)。**通过工具调用和沙箱(sandbox)机制,将部分上下文(如工具返回的数据、图片、音频等)隔离在外部环境,而不是直接传给LLM。这样可以有效管理和存储大体积的状态信息,让LLM只处理最相关的内容,提高上下文的有效利用率。
最后让我们看看karpathy老师是怎么理解Context Engineering的
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.”