Context Engineering Explained
Context is the real bottleneck in an LLM product. A frontier model without the right context is like an elite intern dropped into a task with no brief, no target, no tools, and no history. It may still be capable, but it will not perform consistently. The problem is that context is always scarce. As the context window fills up, quality often drops while cost and latency become harder to control.
What Is Context Engineering?
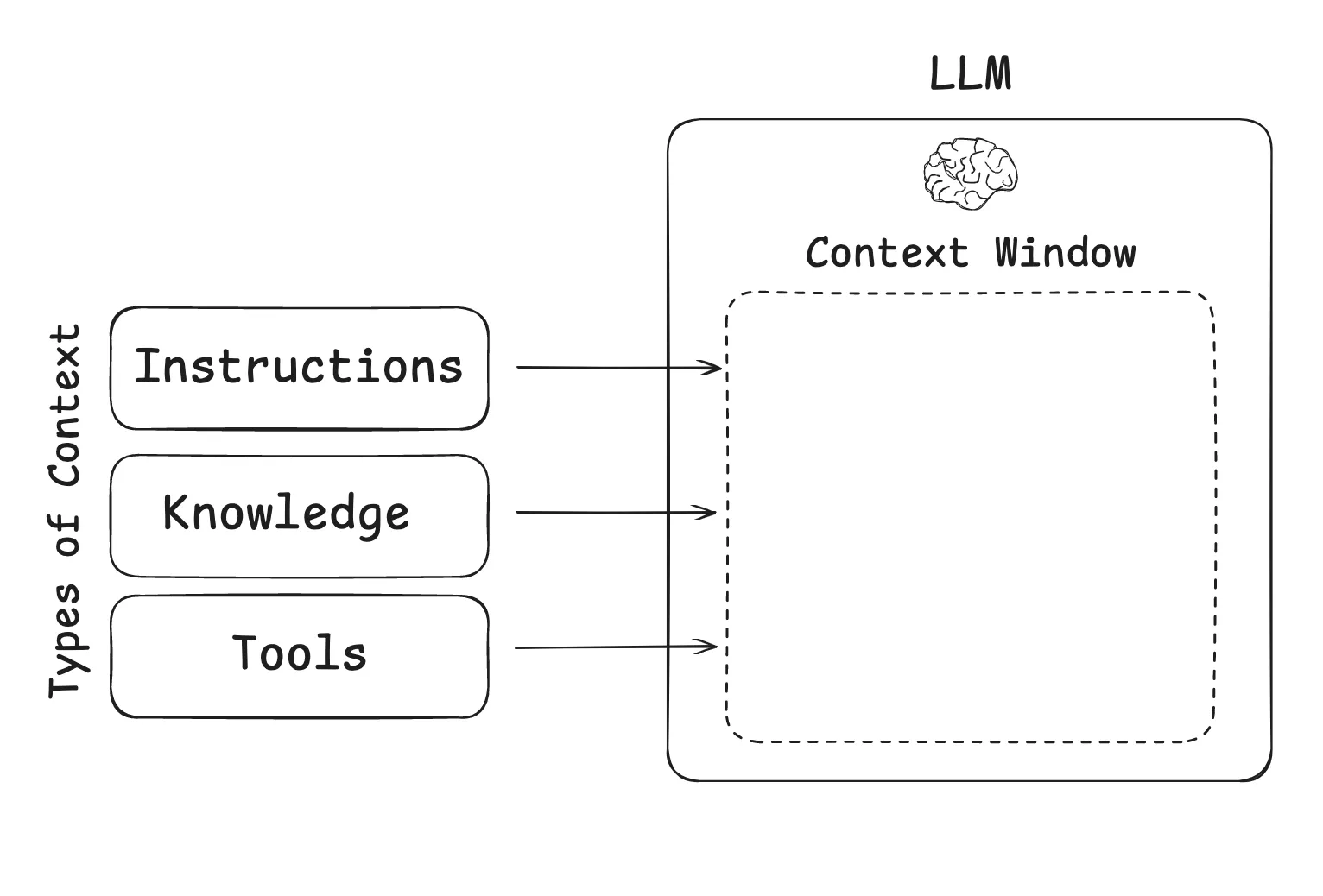
In practice, context usually contains three broad categories:
- Instructions: prompts, memory, few-shot examples, and tool descriptions
- Knowledge: facts, retrieved documents, and stored memory
- Tool feedback: observations returned by tools and external systems
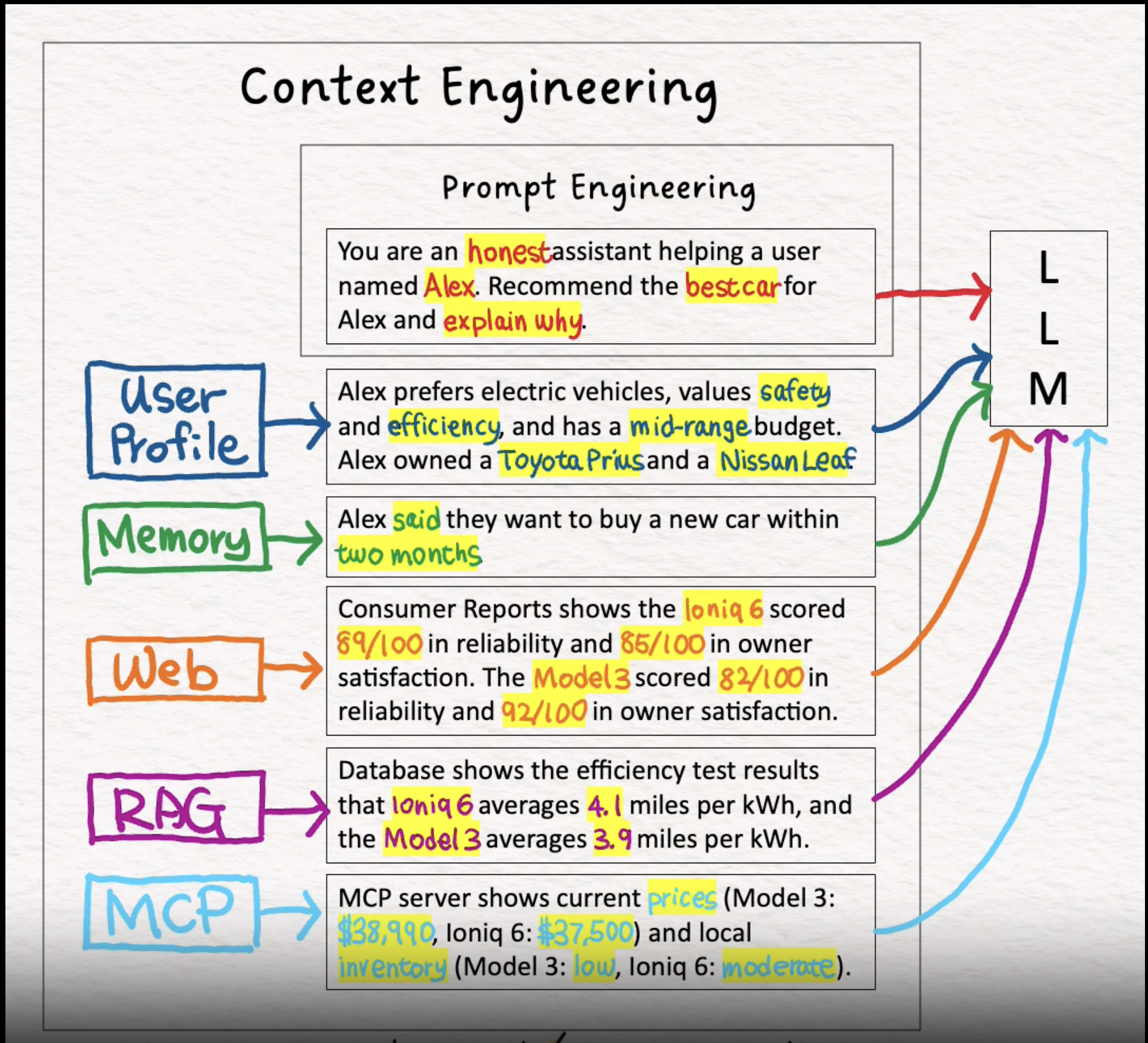
Google DeepMind engineer Philipp Schmid breaks context down even further:
- Instructions / system prompt: the initial rules, examples, and constraints that shape model behavior
- User prompt: the immediate task or question from the user
- State / history (short-term memory): the current conversation and the steps that led here
- Long-term memory: persistent knowledge such as user preferences, past projects, or reusable facts
- Retrieved knowledge (RAG): external and up-to-date information from documents, databases, or APIs
- Available tools: the functions or built-in tools the model can call
- Structured output: response format requirements such as JSON schemas
His definition is still the clearest one I have seen:
Context engineering is the discipline of designing and building dynamic systems that provide the right information and tools, in the right format, at the right time, so an LLM can complete a task.
A useful analogy is this: the LLM is the CPU, and the context window is RAM. RAM is limited, so the operating system decides what should be loaded at any given moment. Context engineering plays the same role for LLM systems.
Why Agents Need Context Engineering
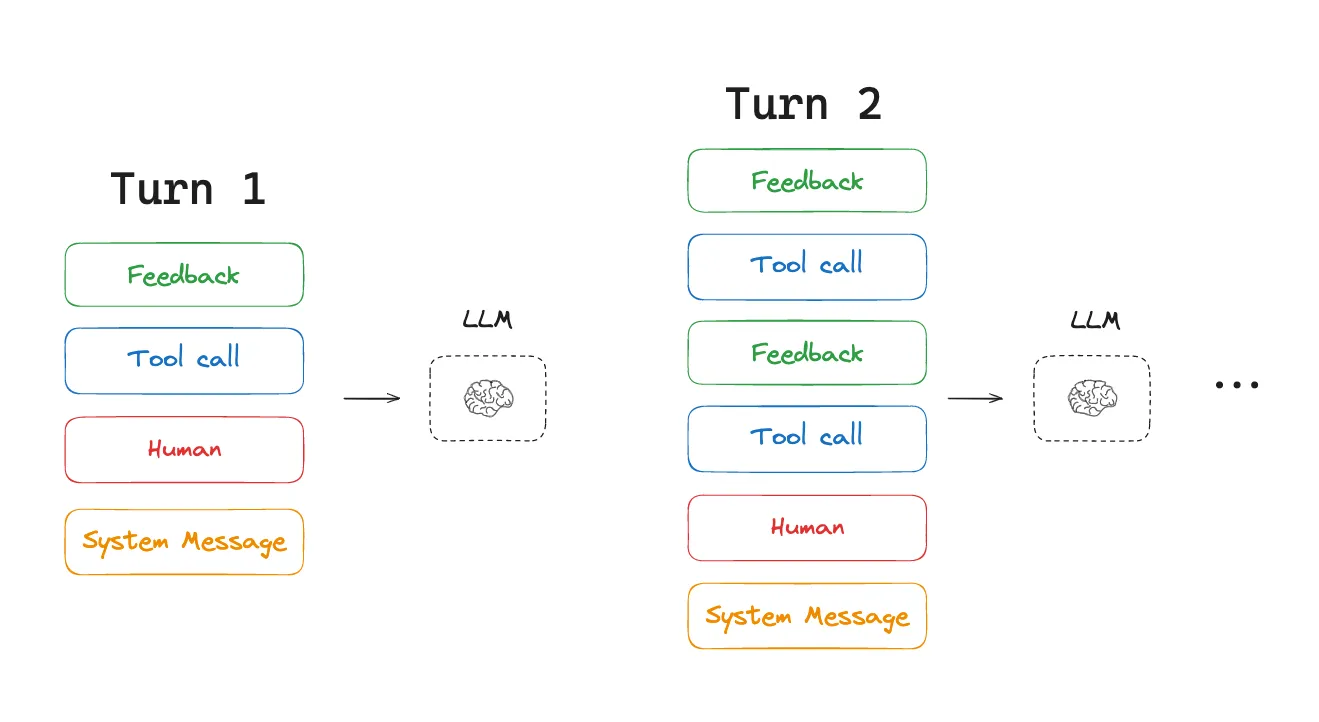
Consider a typical agent workflow. The user gives a task. The agent chooses an action from a predefined action space, calls a tool, receives an observation, appends that observation to context, and then repeats the cycle until the task is done.
That means context grows at every step, while the output at each step is usually quite short, often just a structured tool call. Compared with a normal chatbot, the ratio between prefill and decoding becomes badly imbalanced.
The loop usually looks like this:
- Choose an action: the model inspects the current context and selects what to do next.
- Execute and observe: the action runs in the environment and returns an observation.
- Update context: the action and observation are appended to history.
- Repeat: the expanded context becomes the input for the next step.
The core challenge is obvious: the harder the task, the more tokens the agent consumes. Eventually you hit one or more of the following problems:
- the context window overflows
- cost and latency spike
- the agent's performance degrades
Context engineering is the set of practical strategies we use to control that growth. The four most useful buckets are write, select, compress, and isolate.
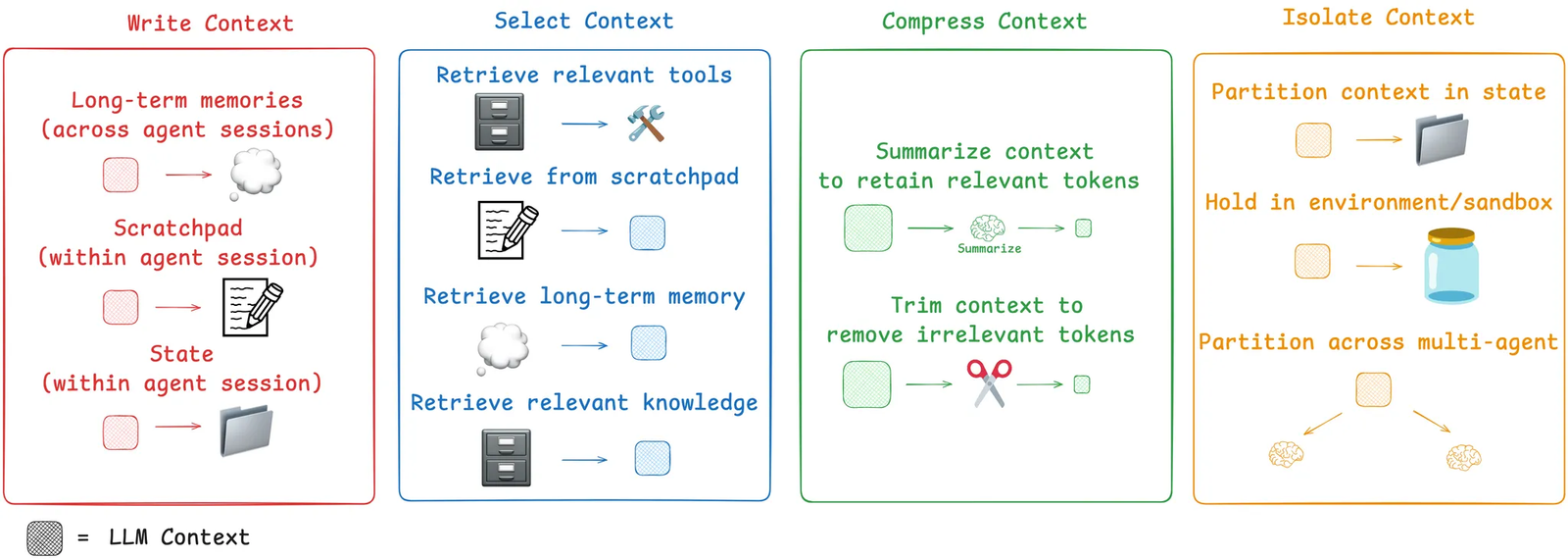
Write
Writing context means saving information outside the context window so the agent can still use it later.
Scratchpads and Memory
Humans take notes because memory is unreliable. Agents need the same habit. A scratchpad can be a file, a database record, or any persistent program object where the agent stores intermediate facts, plans, and checkpoints.
Scratchpads are usually temporary. They help inside a single session and are often discarded once the task ends.
Anthropic has shown this pattern in multi-agent research systems. A lead researcher agent writes plans into memory so that even if the context window overflows, the core strategy is preserved. We see the same idea in Manus: during planning, it creates a todo.md, updates it after each step, and feeds that artifact back into the workflow.


Unlike a scratchpad that only works inside one session, long-term memory lets an agent retain user preferences, historical experience, and reusable facts across sessions.
Select
Selection matters as much as storage. An agent does not just select from scratchpads and memory. It also needs to select the right tools, the right knowledge, and the right examples.
Too much context makes a model slower, weaker, and sometimes confused. Good context engineering is therefore not just about adding information. It is about choosing the minimum set of high-value information for the current step.
Compress
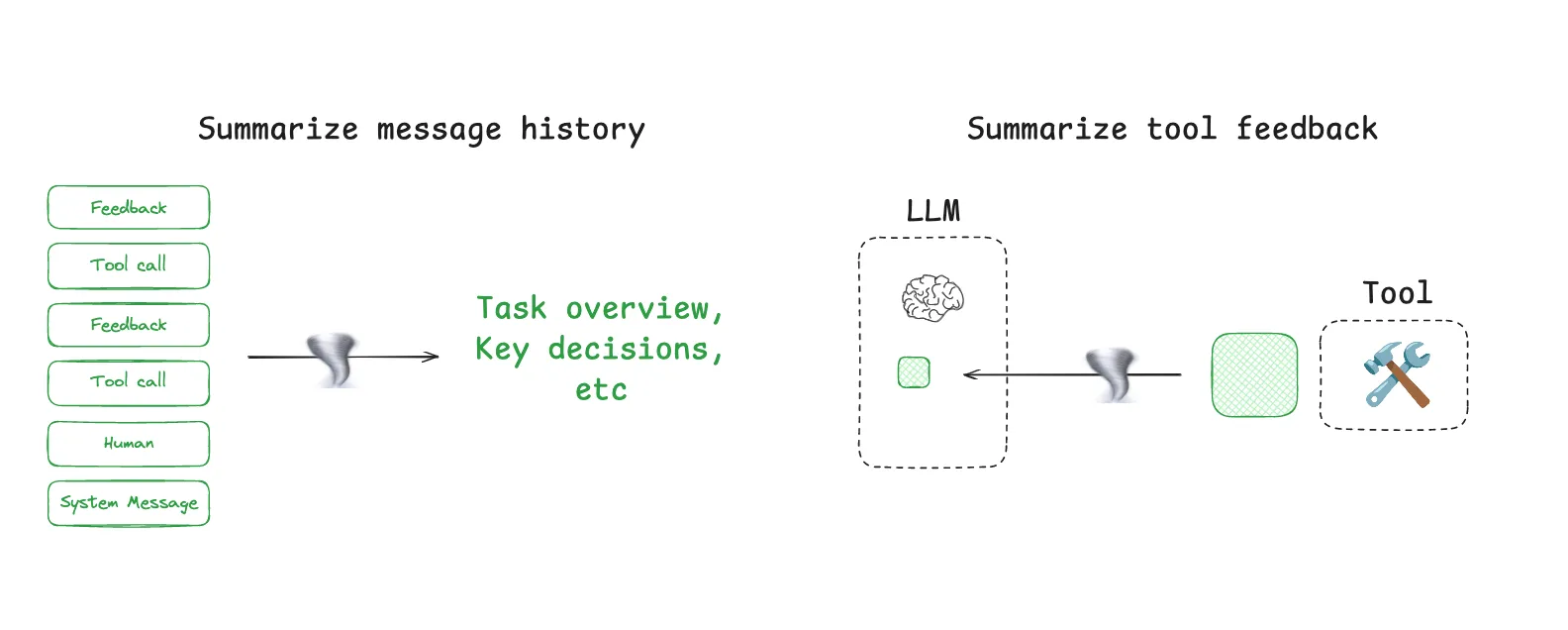
Compression is the most direct response to limited context windows. In practice, there are two common approaches: trim and summarize.
Summarization means converting a long history into a shorter representation while keeping the key facts. Claude Code does this automatically when usage approaches 95 percent of the context window. Manus also does something similar when a session becomes too large and the system offers to inherit context into a fresh session.
Trimming is simpler: remove the parts that seem less important and keep the rest. This can reduce cost and length quickly, but it risks deleting the very detail the model needed.
Isolate
Isolation means separating task-relevant context so the agent can operate in smaller, cleaner scopes.
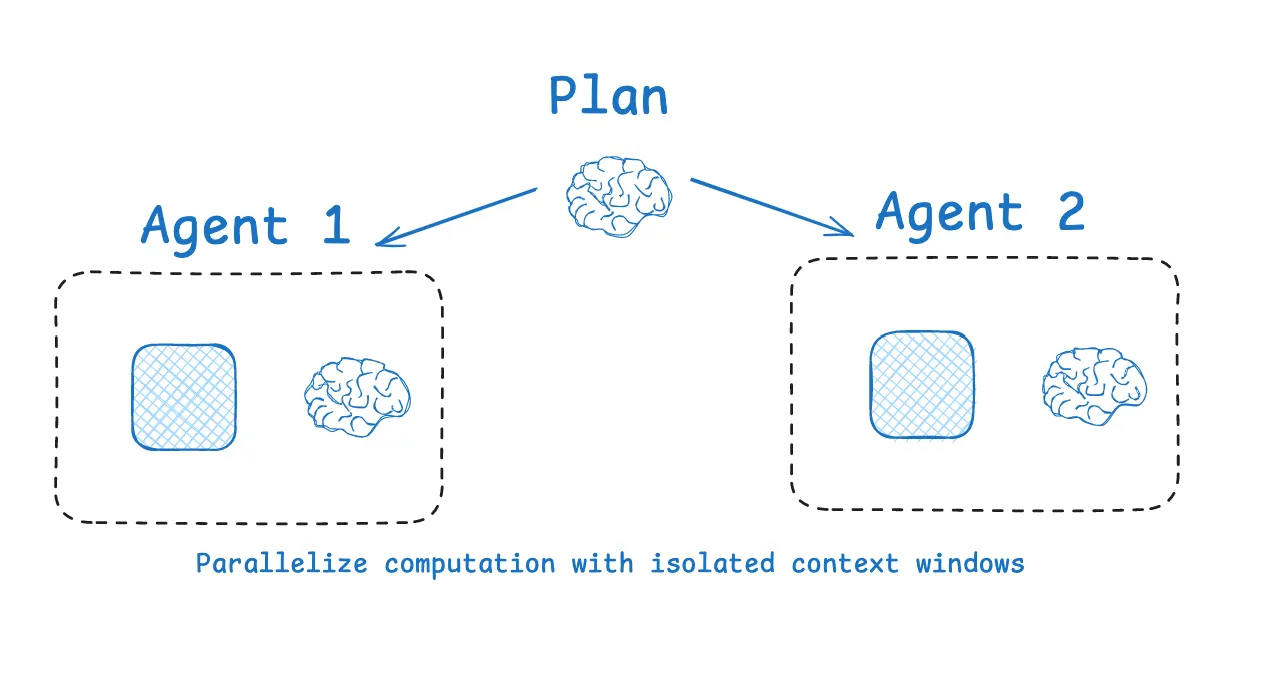
One approach is multi-agent decomposition. Different sub-agents handle different subtasks, each with its own tools, instructions, and context window. That lets each agent focus on a narrower problem. Anthropic's multi-agent researcher system shows that parallel agents with isolated contexts can outperform a single monolithic agent, though at the cost of more tokens and more coordination overhead.
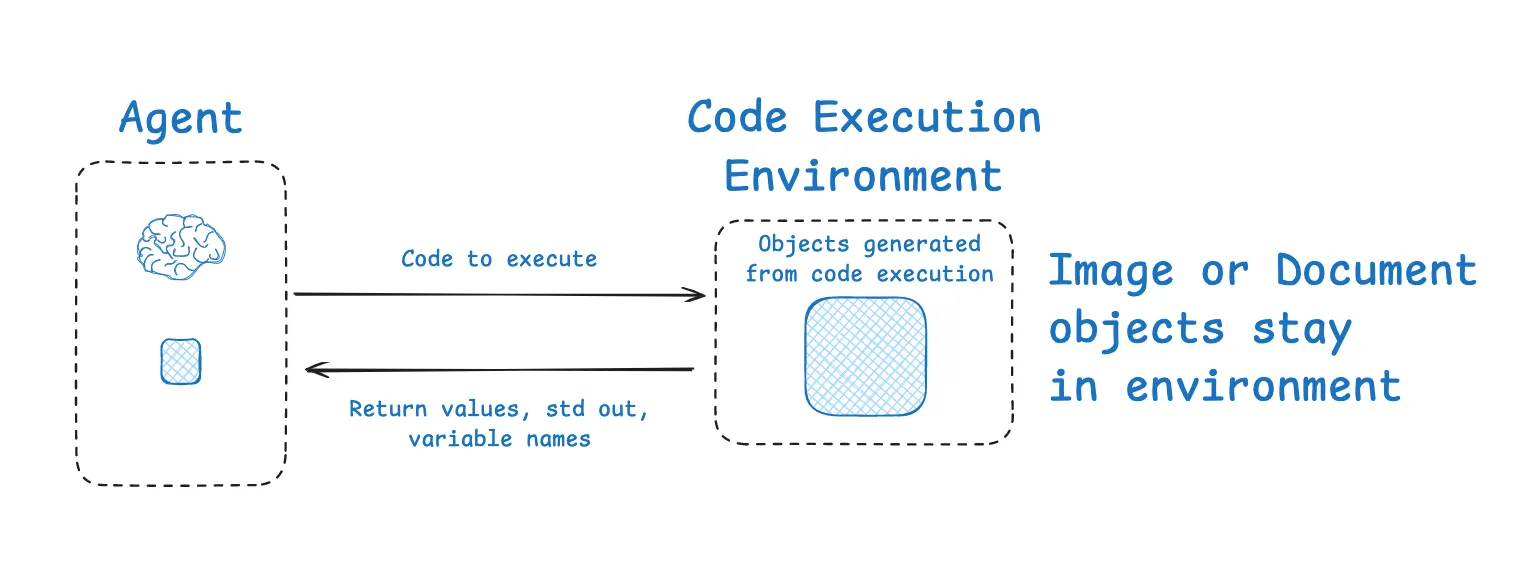
Another approach is environment isolation. Through tools and sandboxed environments, large artifacts such as raw tool outputs, images, and audio can remain outside the LLM's immediate context. The model only sees the most relevant slice, while the environment stores the heavier state.
Karpathy's one-line summary still captures the essence best:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.